Paper Review. Unified Vision Language Pre-Training for Image Captioning and VQA@AAAI’ 2020
Abstract

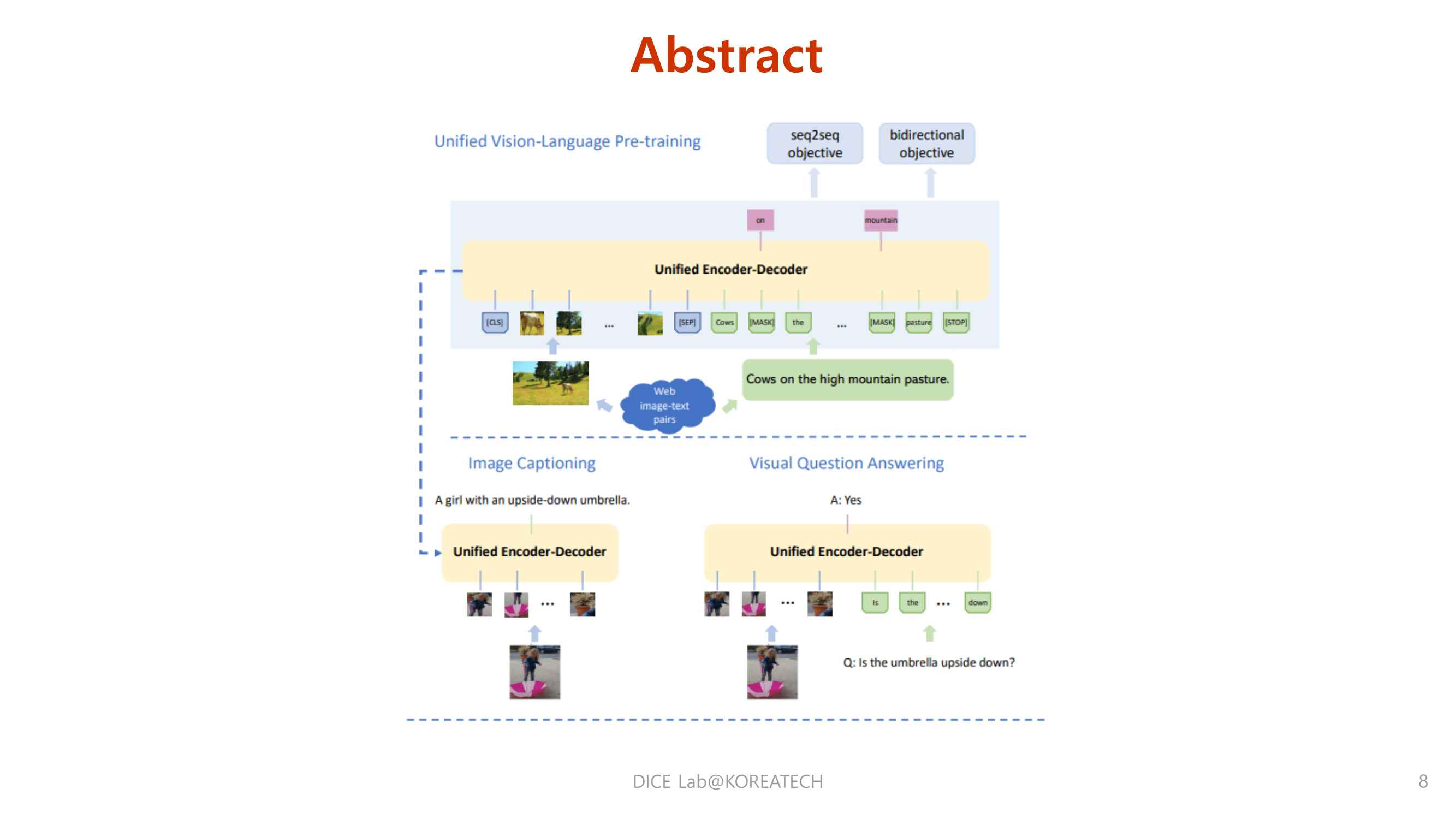
Introduction


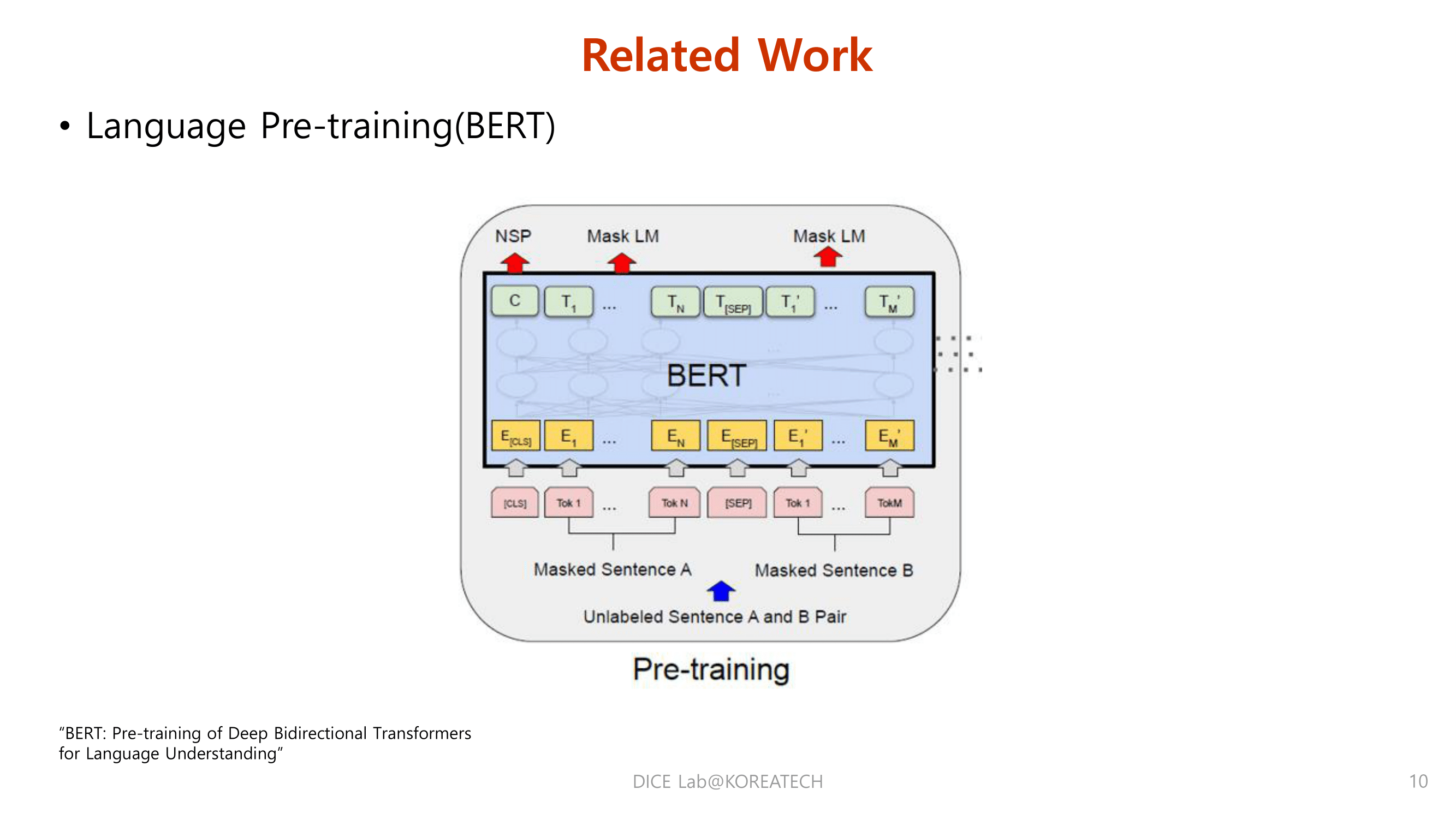
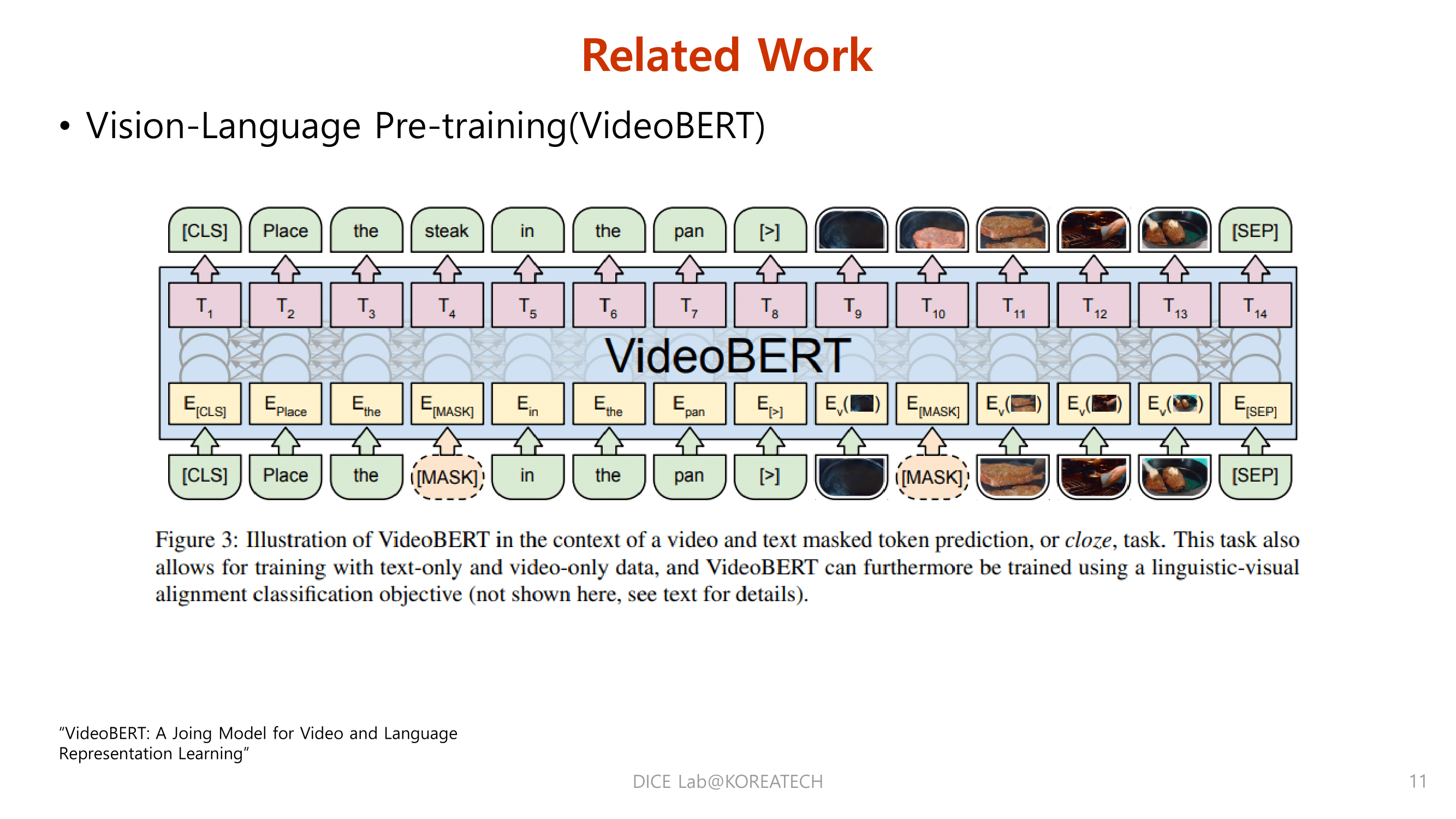
Related Work
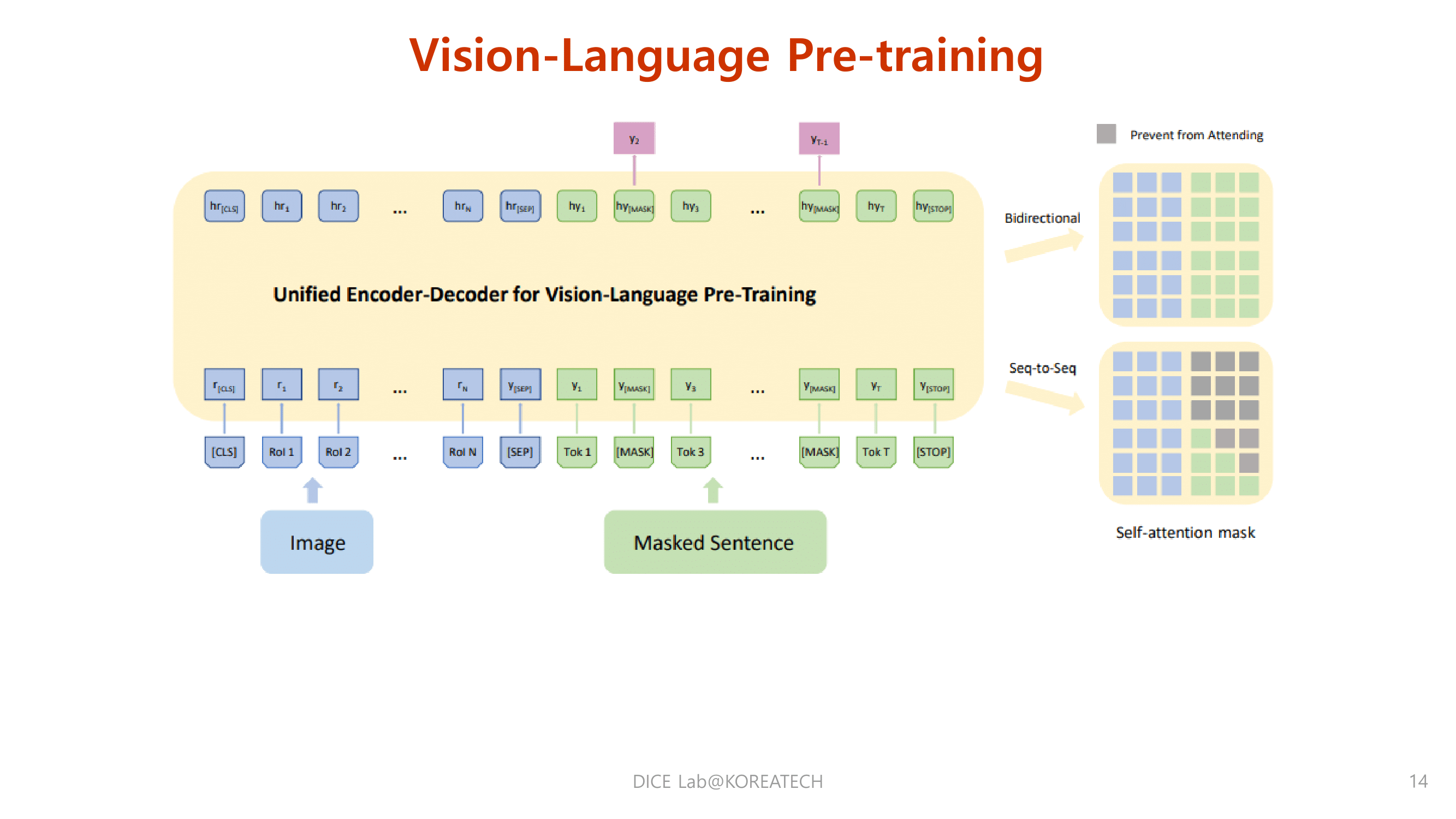
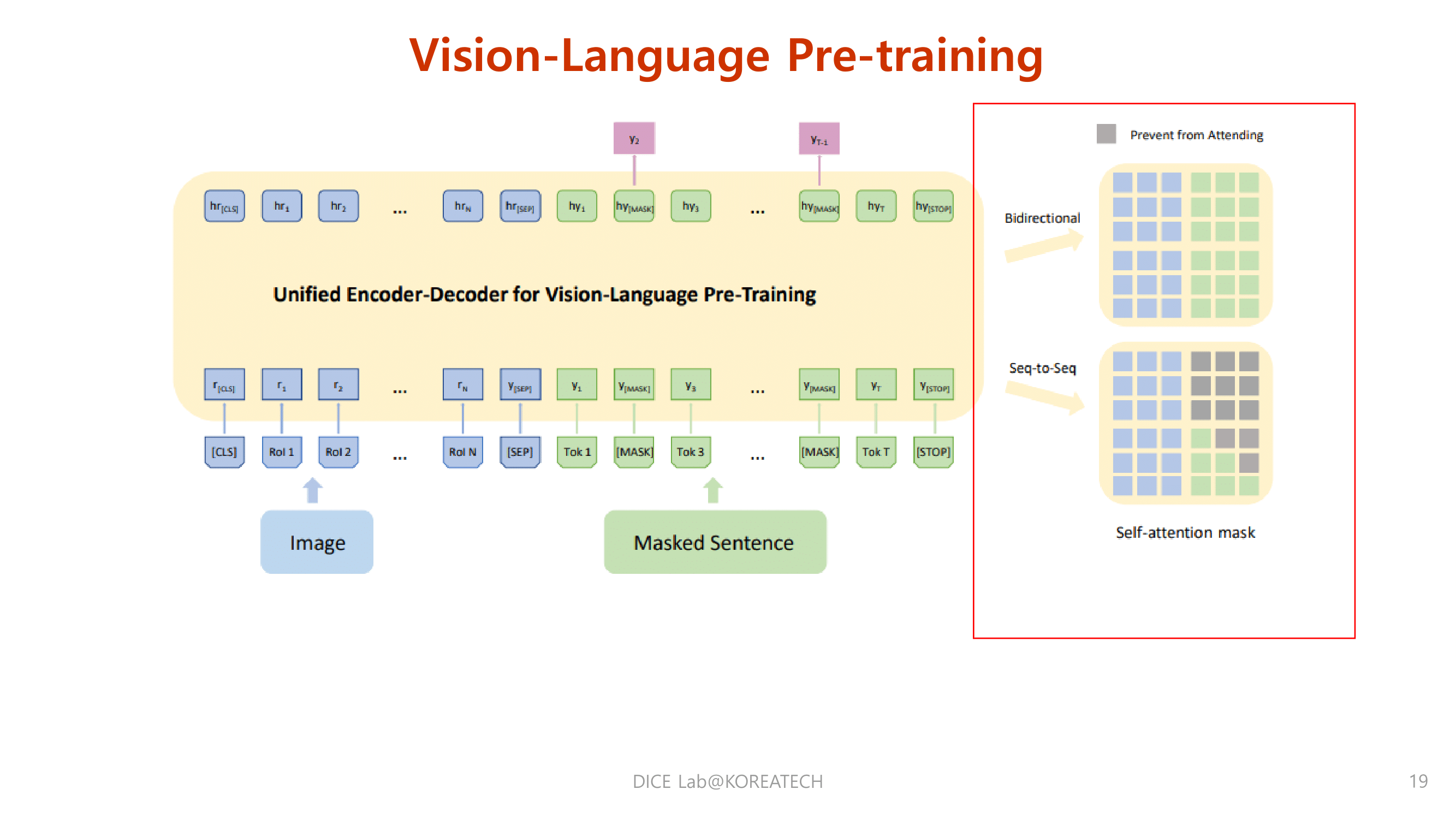
Vision Language Pre training

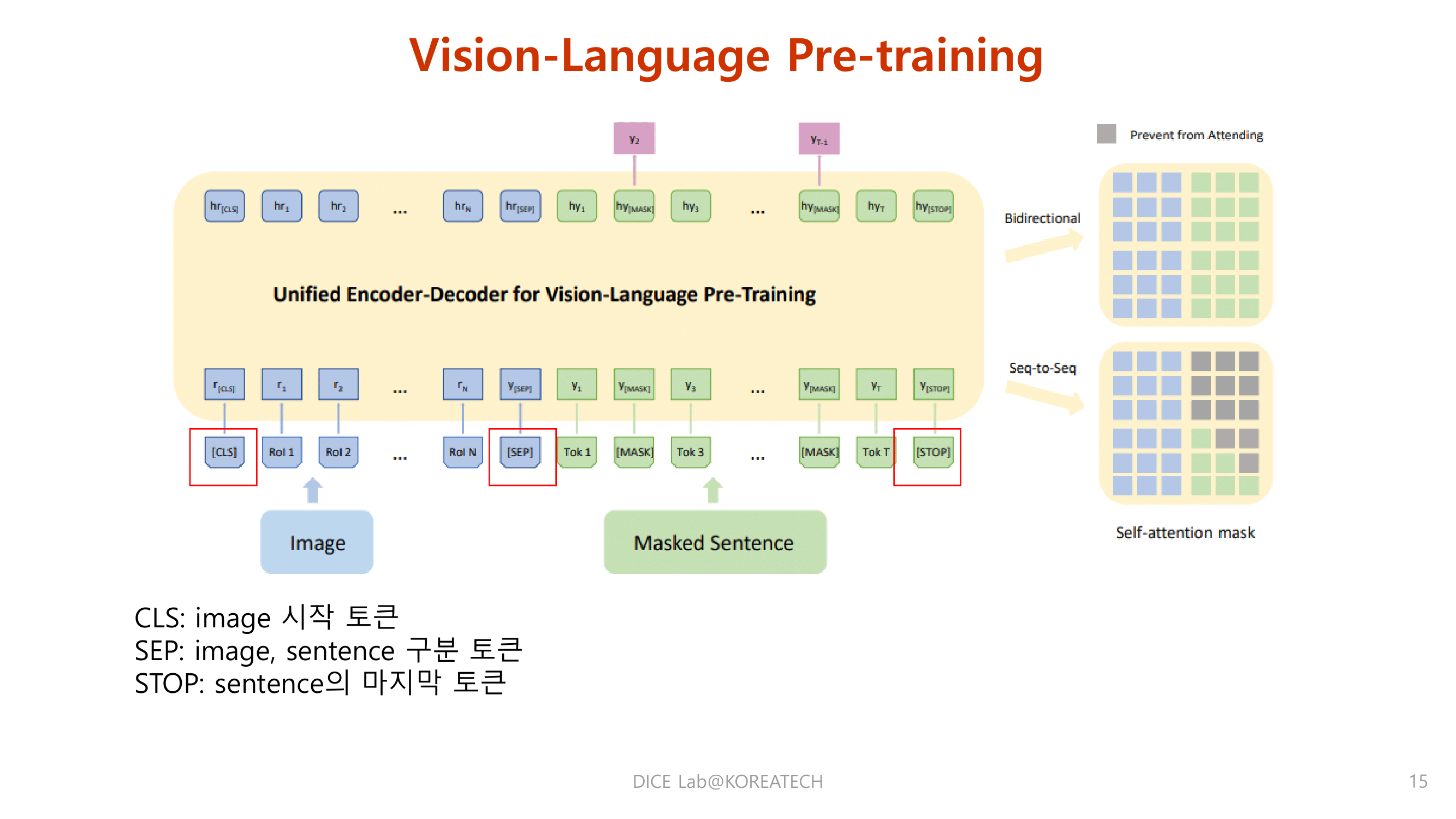
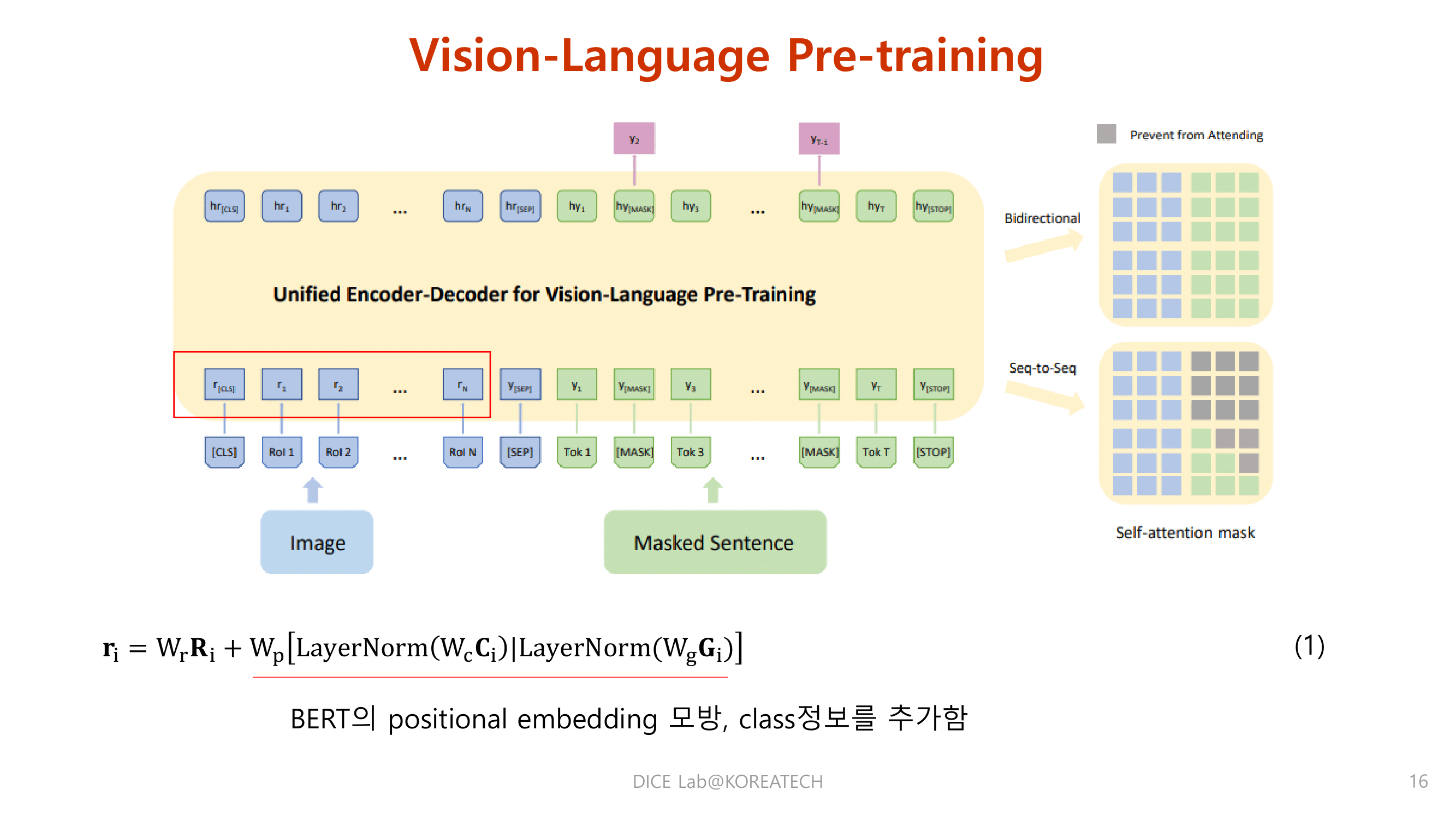
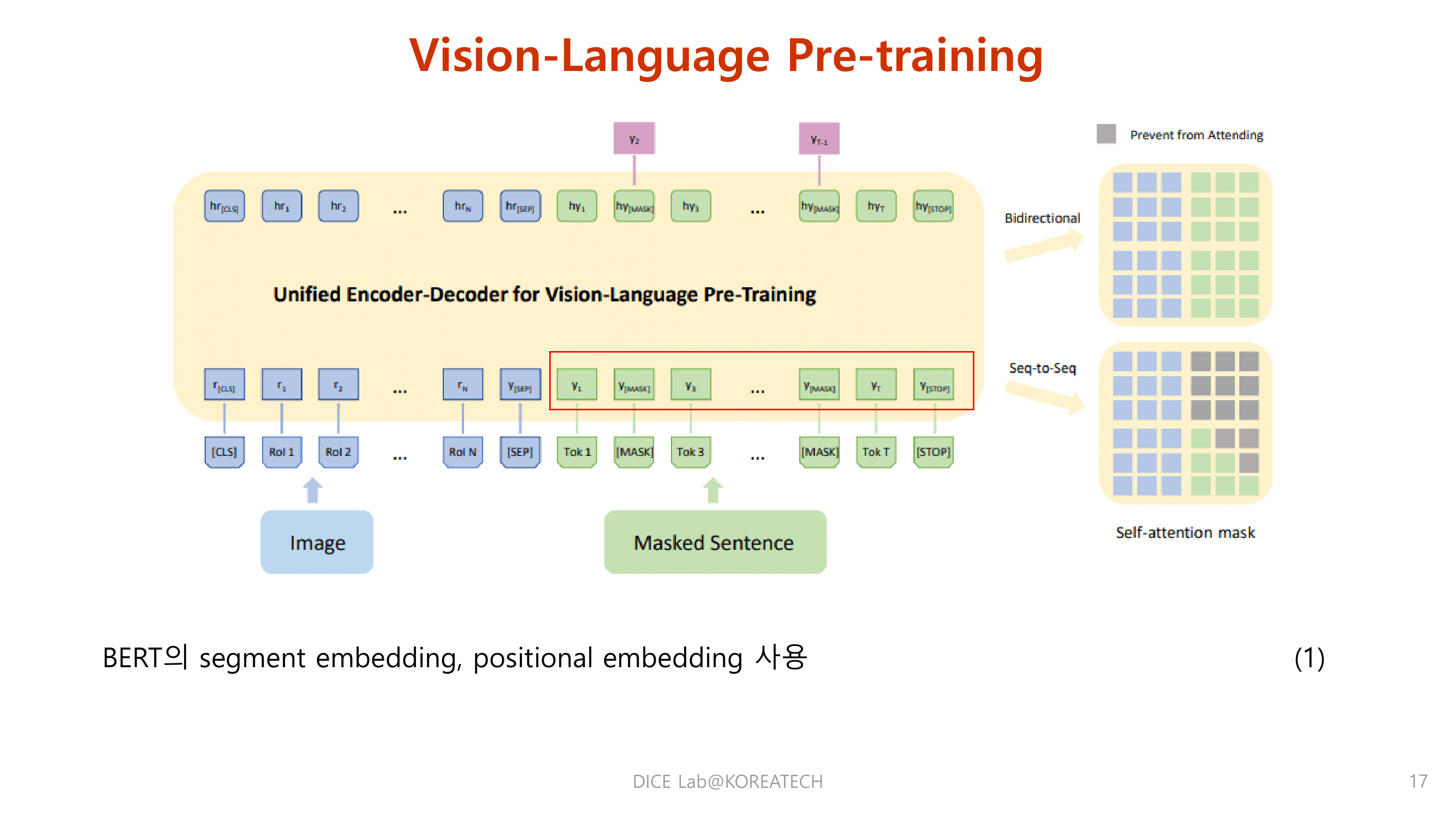
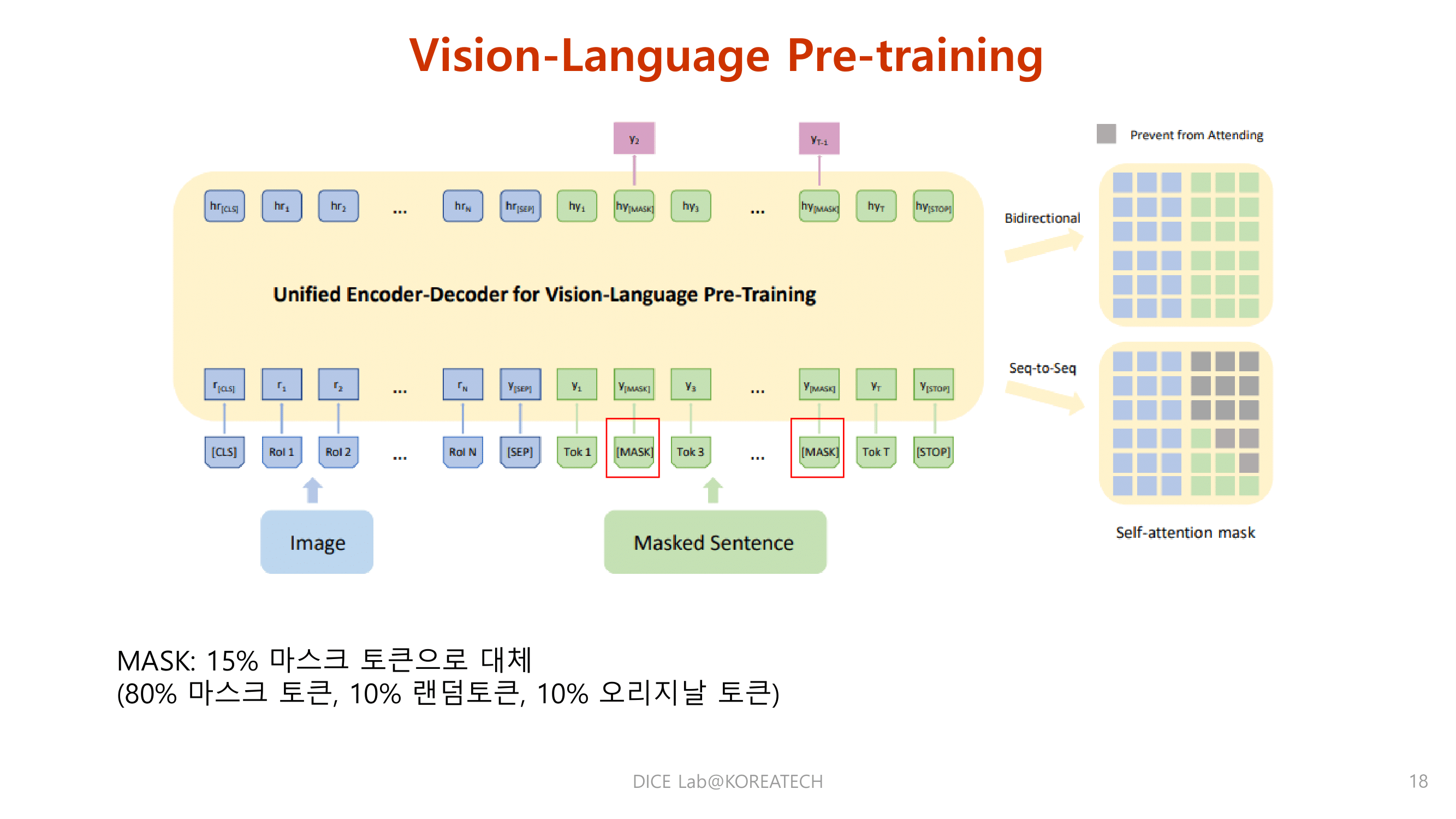



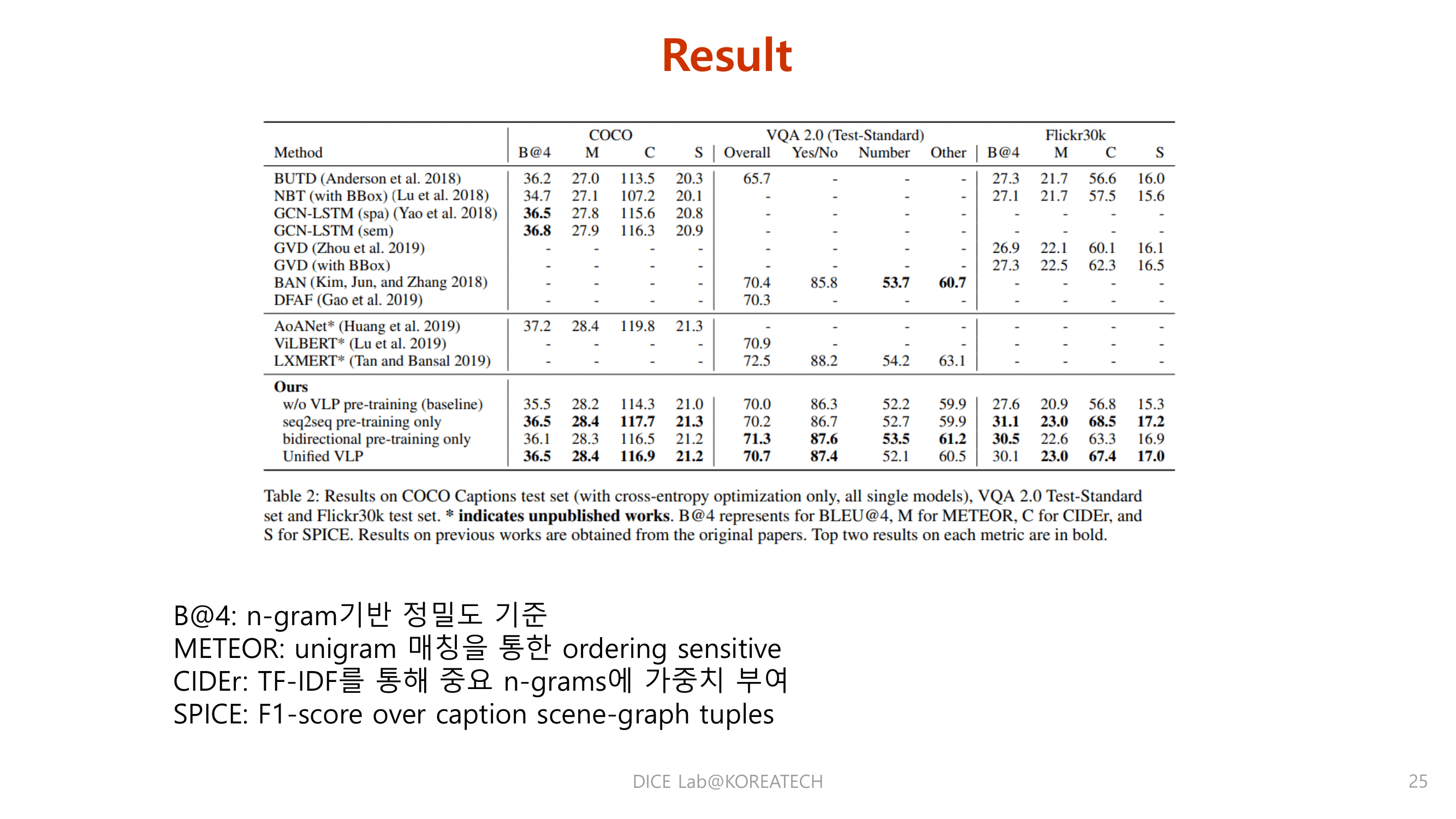
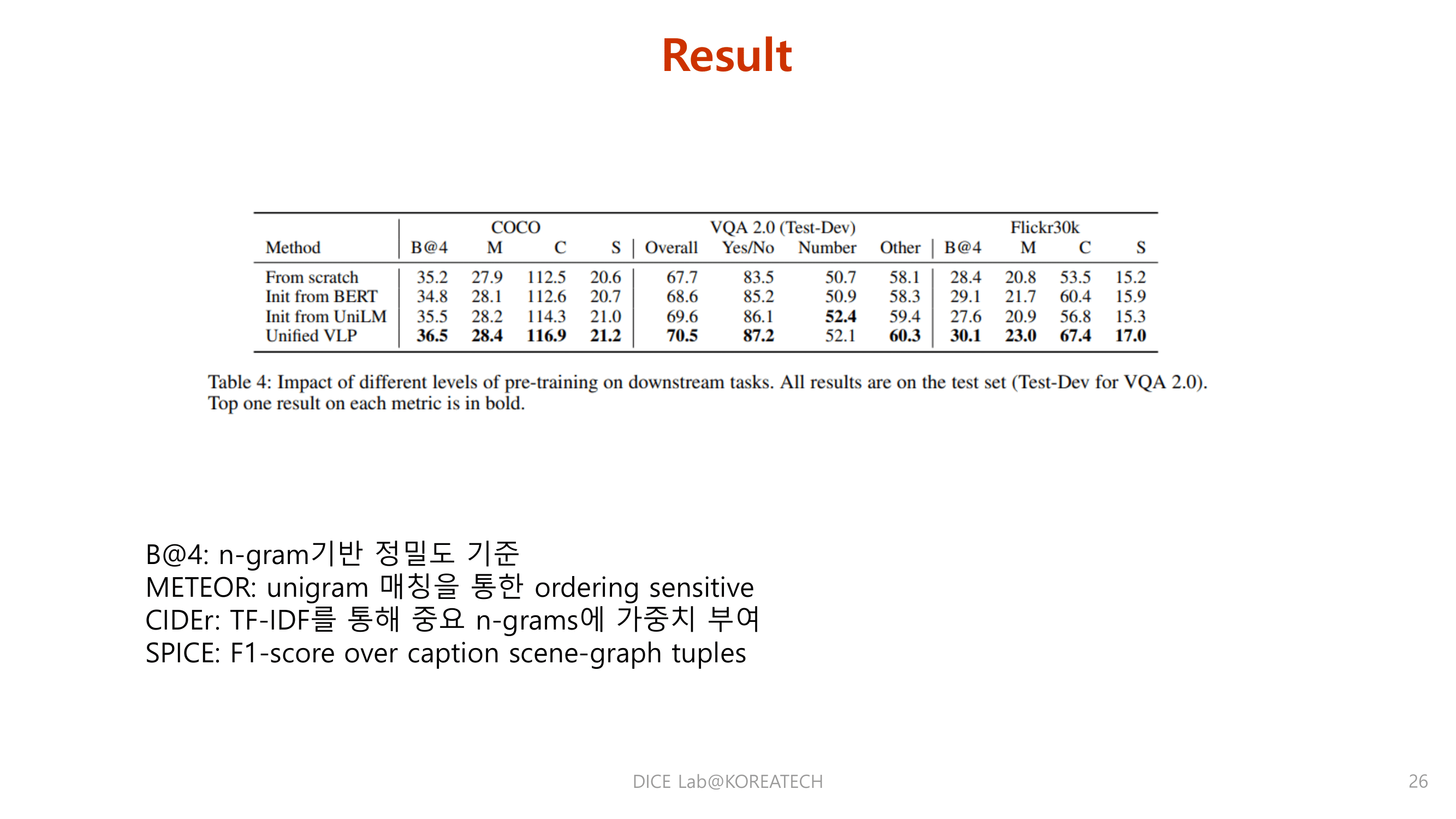
Experiments


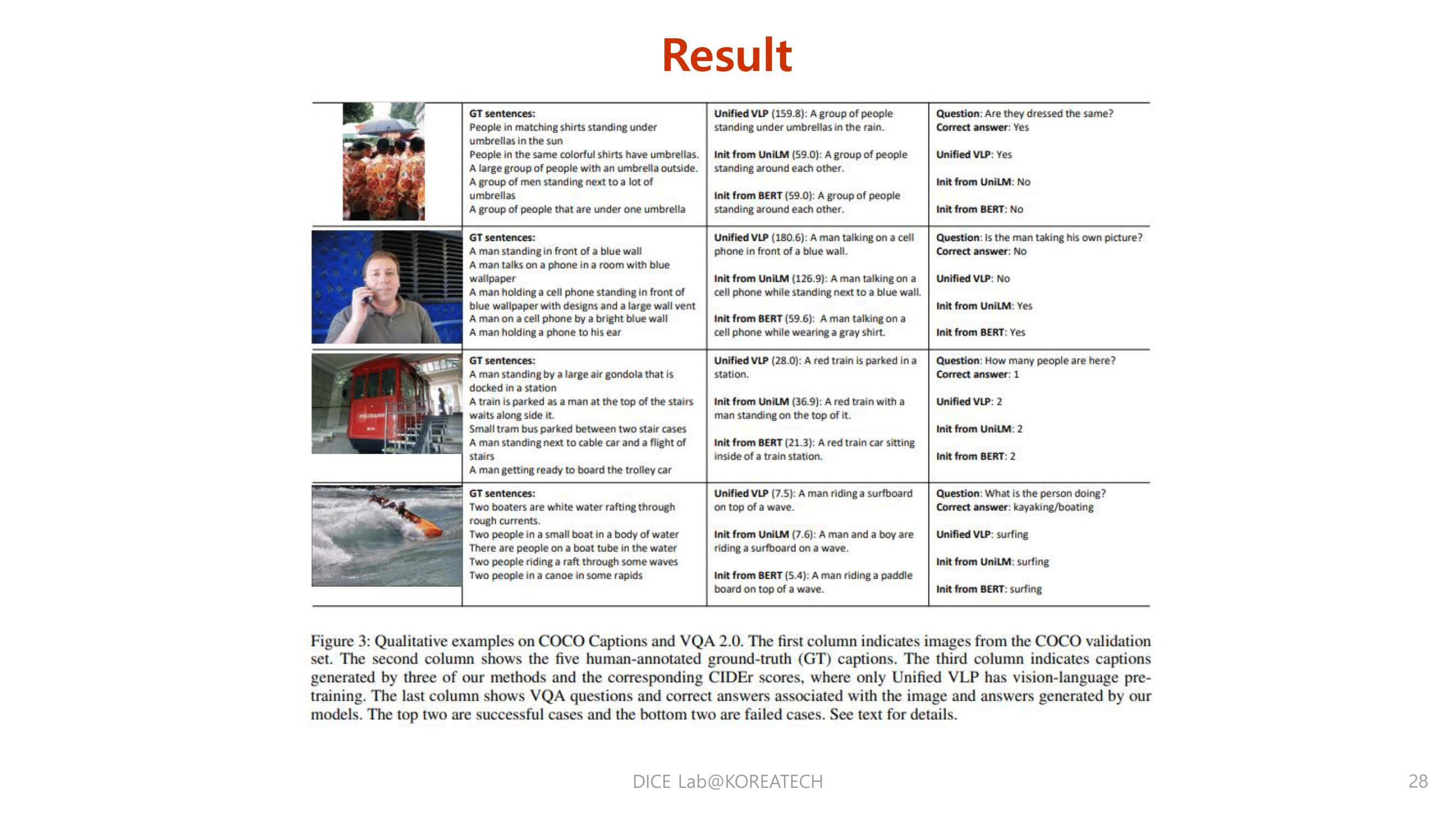
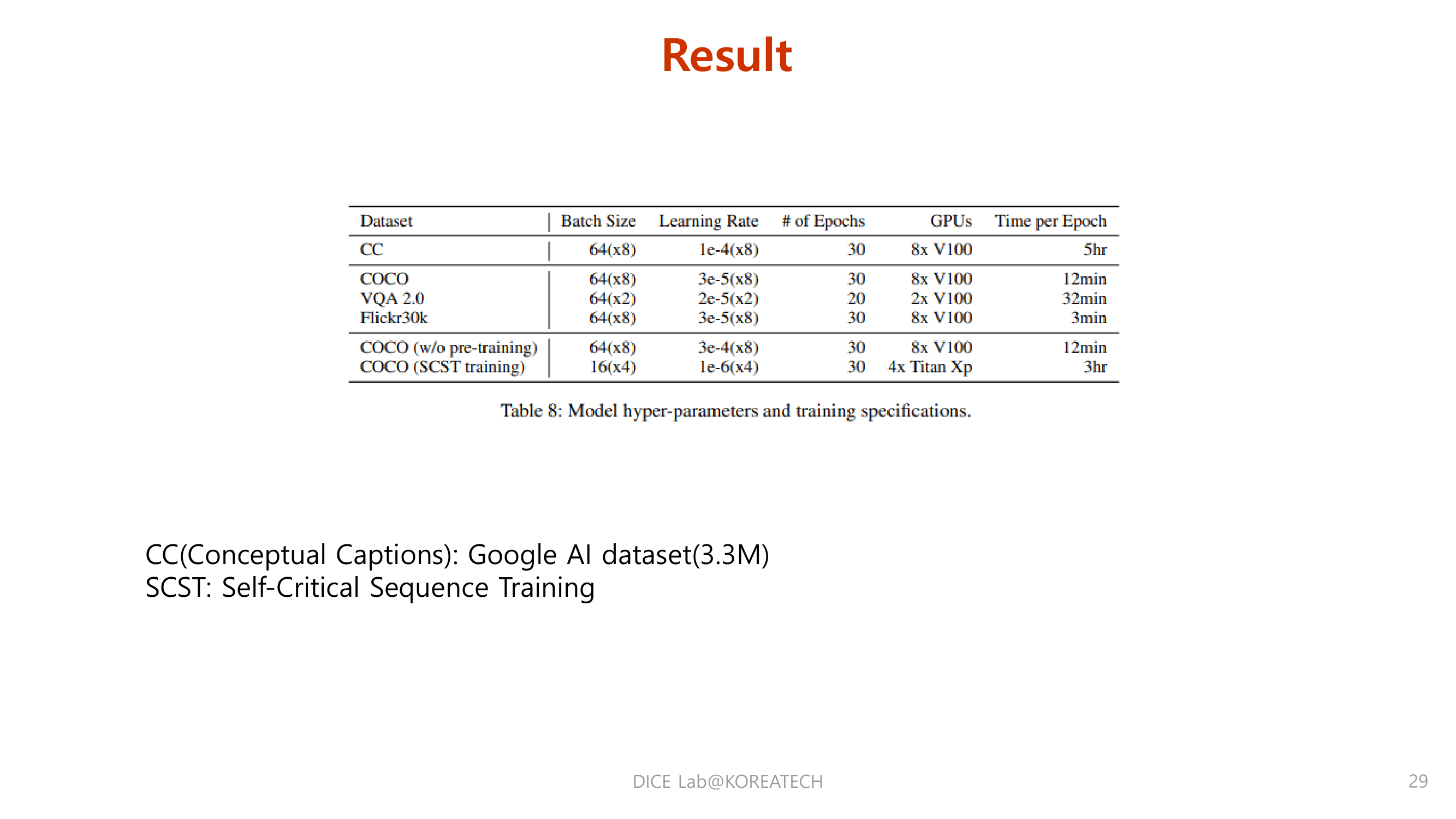
Conclusions & Reviews
Image captioning과 VQA tasks들에 적용할 수 있는 Unified VLP model을 선보임.
대부분의 down stream tasks에서 SOTA 성능을 보임.
encoder decoder를 분리하지 않고 하나의 통합된 모델로 사용하는 점이 흥미로움.
Reference
This post is licensed under CC BY 4.0 by the author.