Paper Review. Training data-efficient image transformers and distillation through attention@ICML’ 2021
Introduction



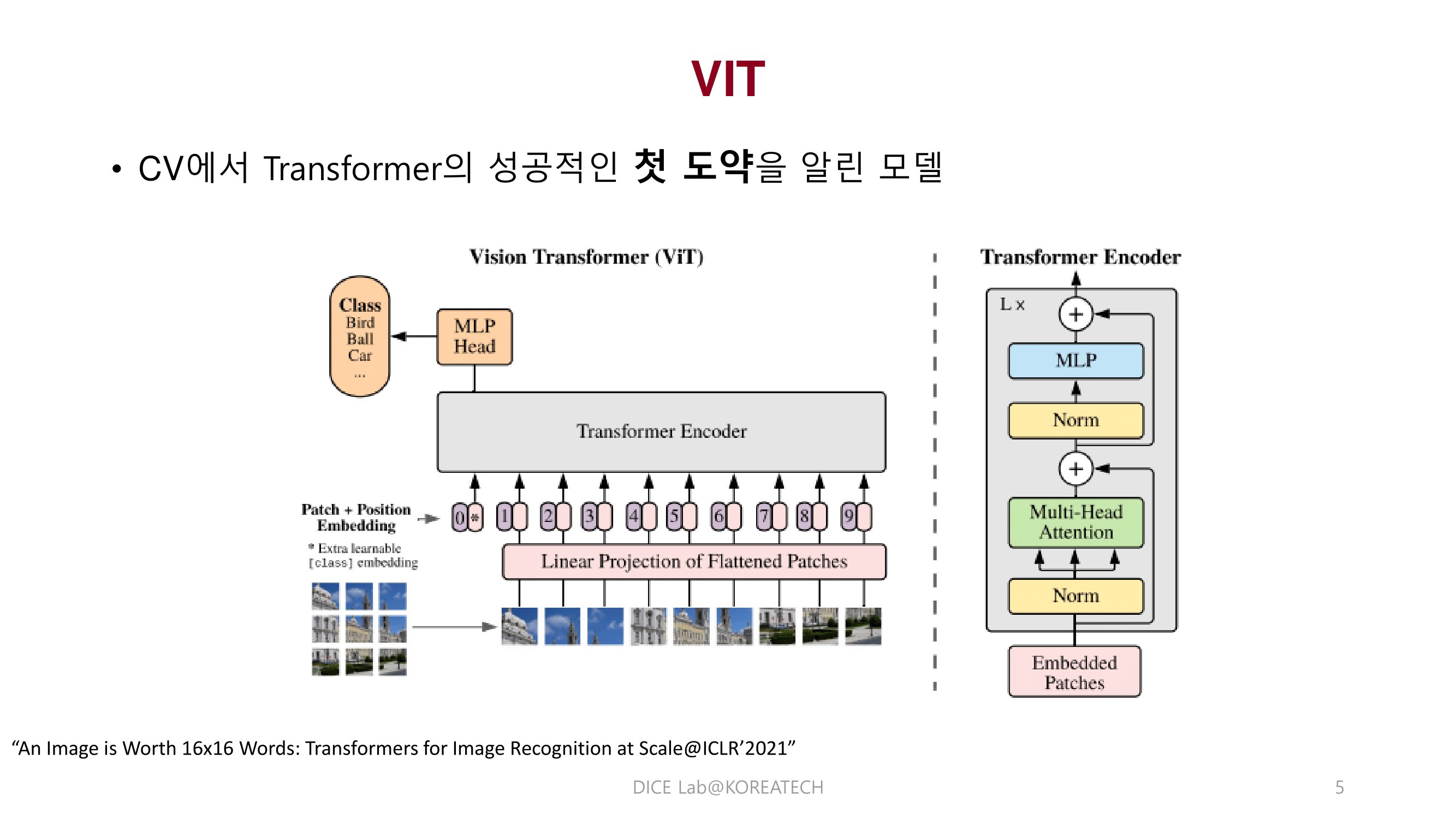








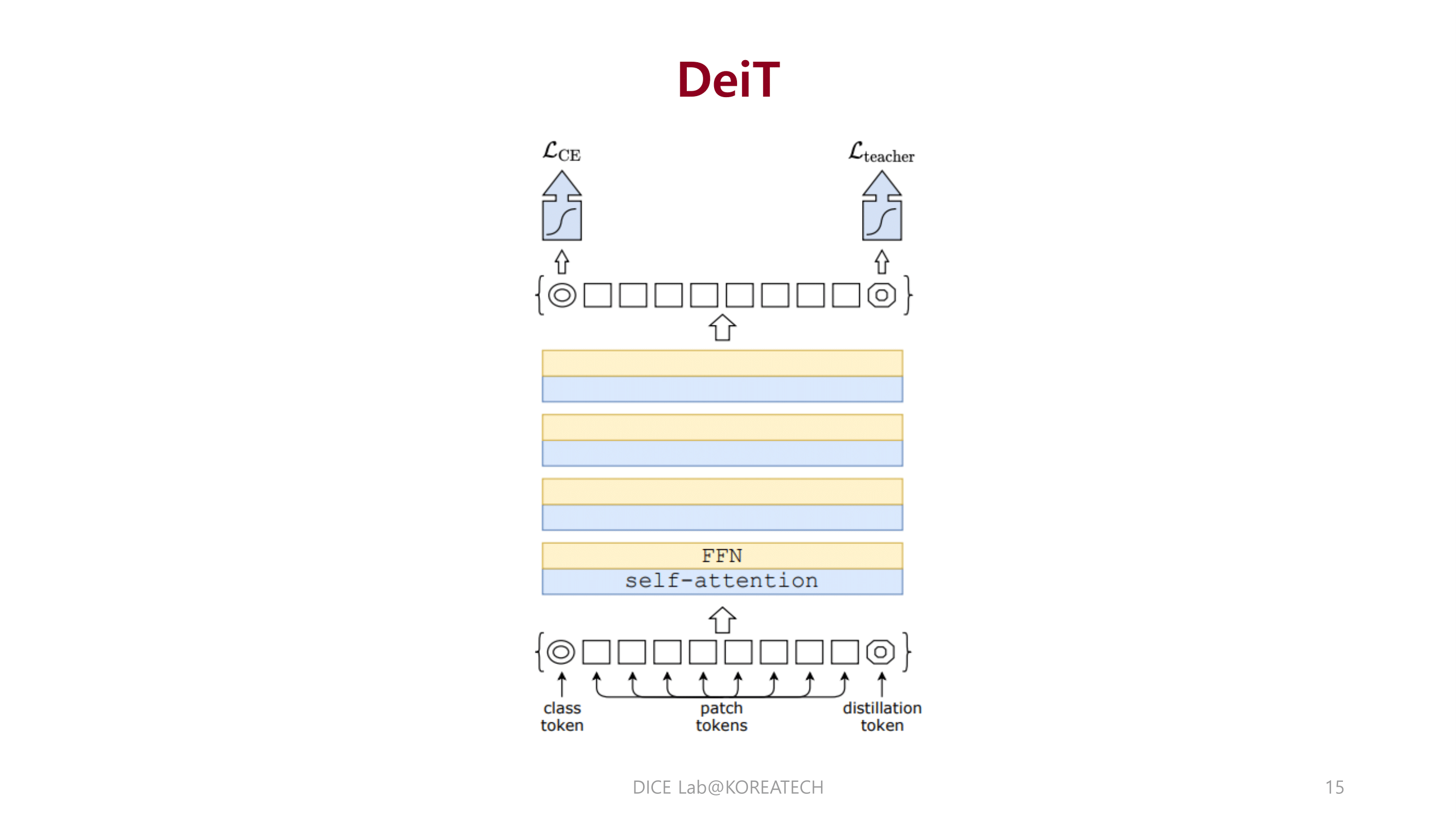
DeiT





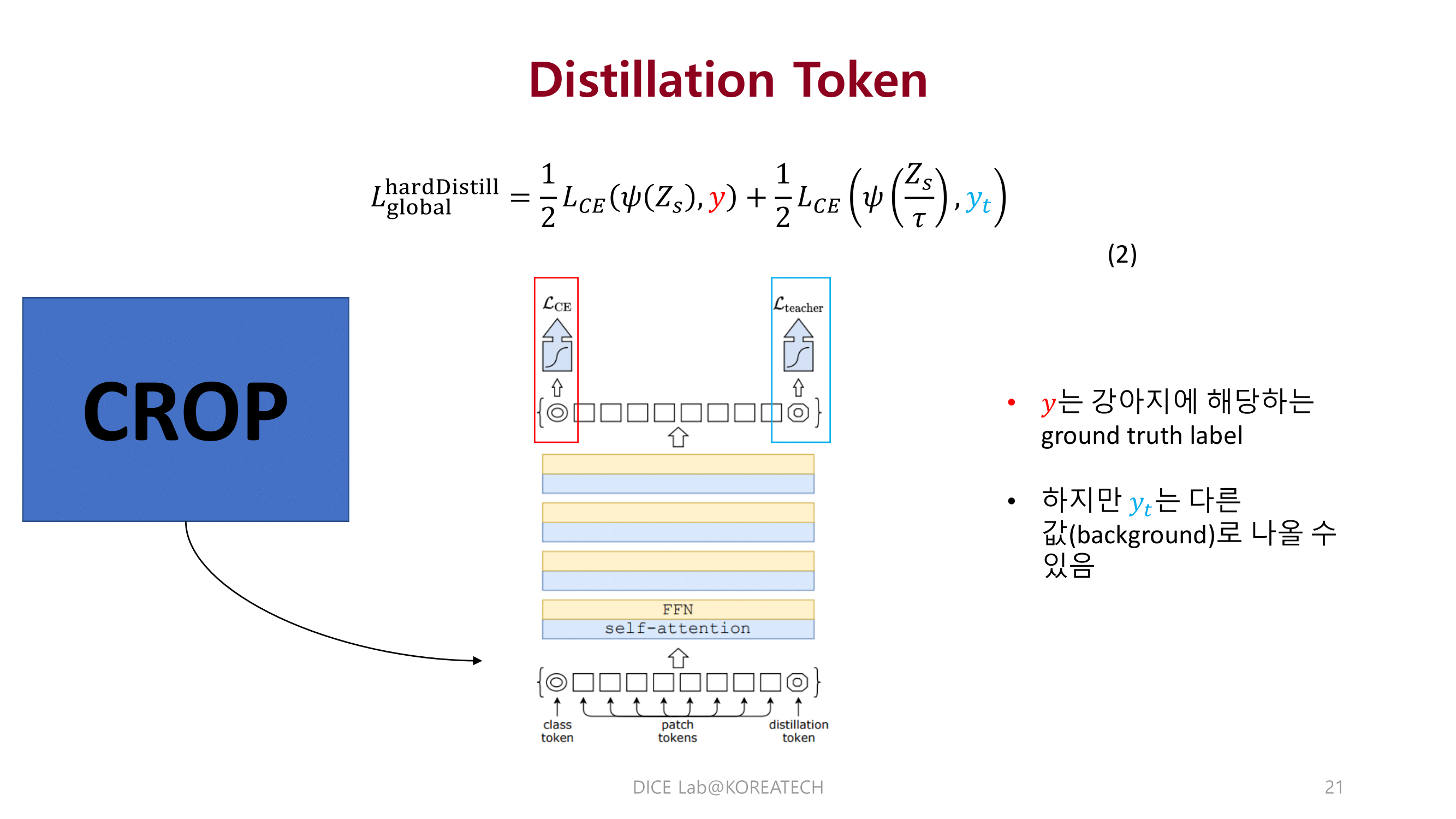

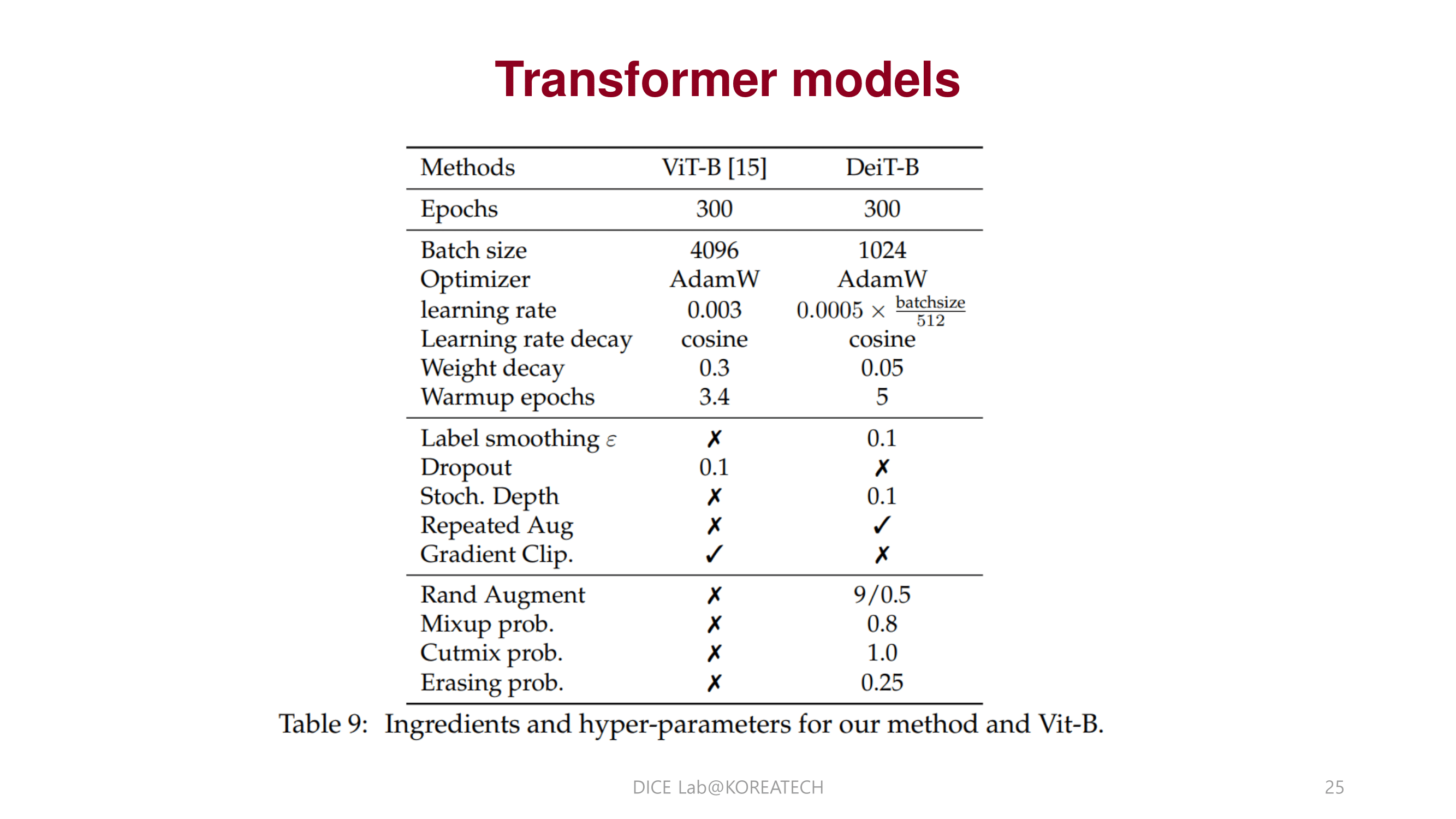
Experiments

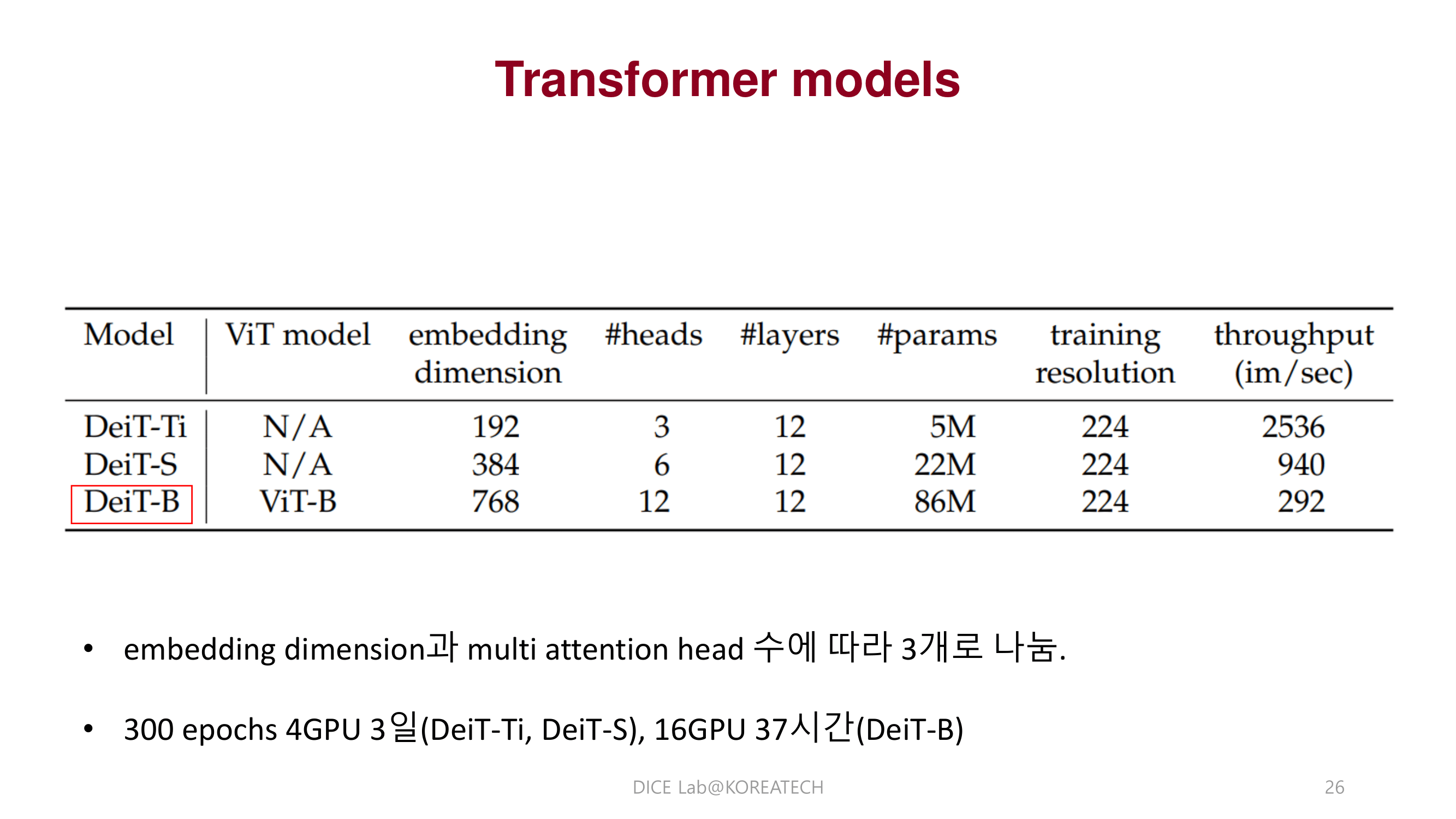
Conclusions & Reviews
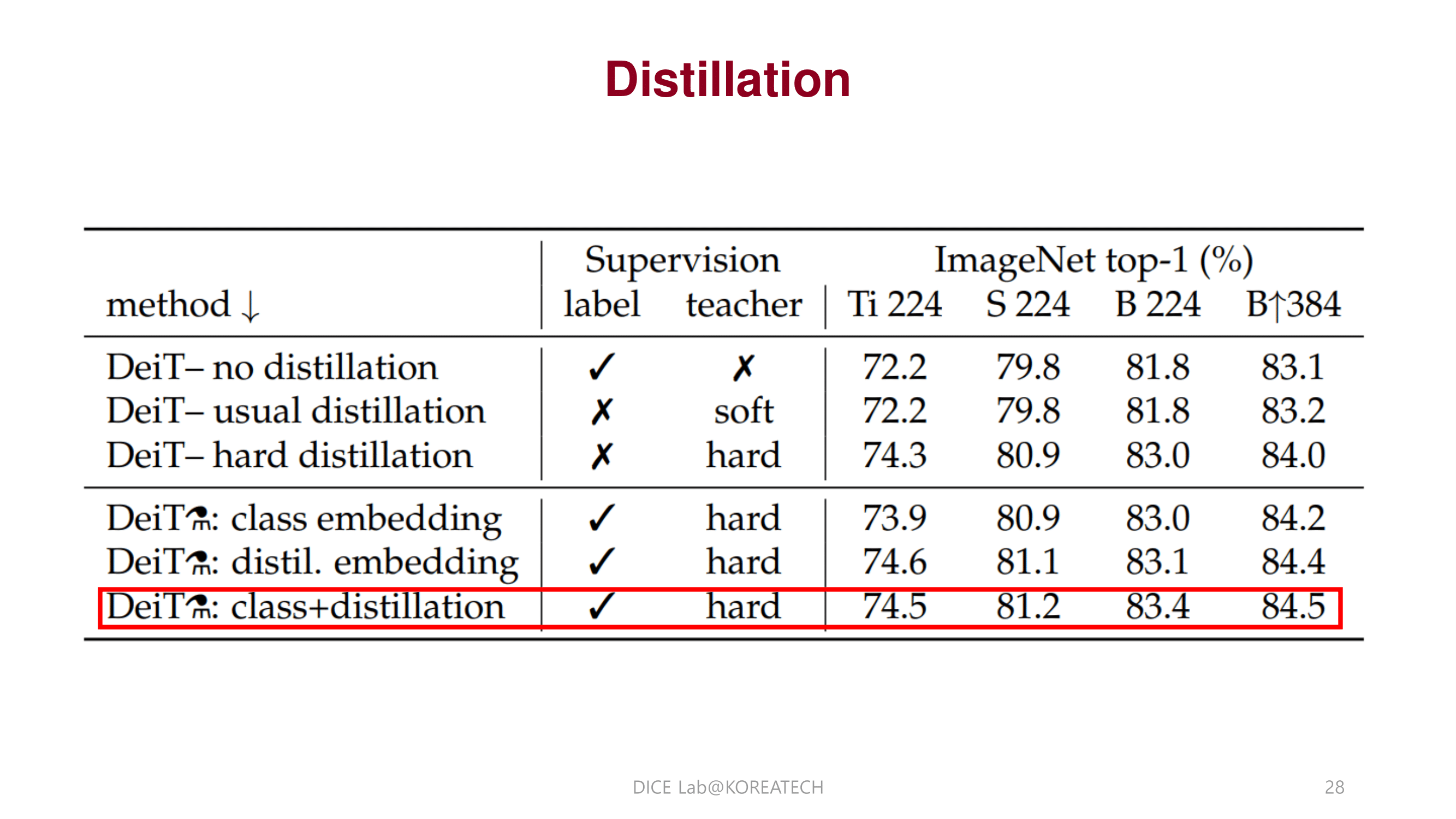
Image Classification에서 비교적 적은 데이터 셋으로도 성능을 끌어 올릴 수 있는 distillation token을 제안함.
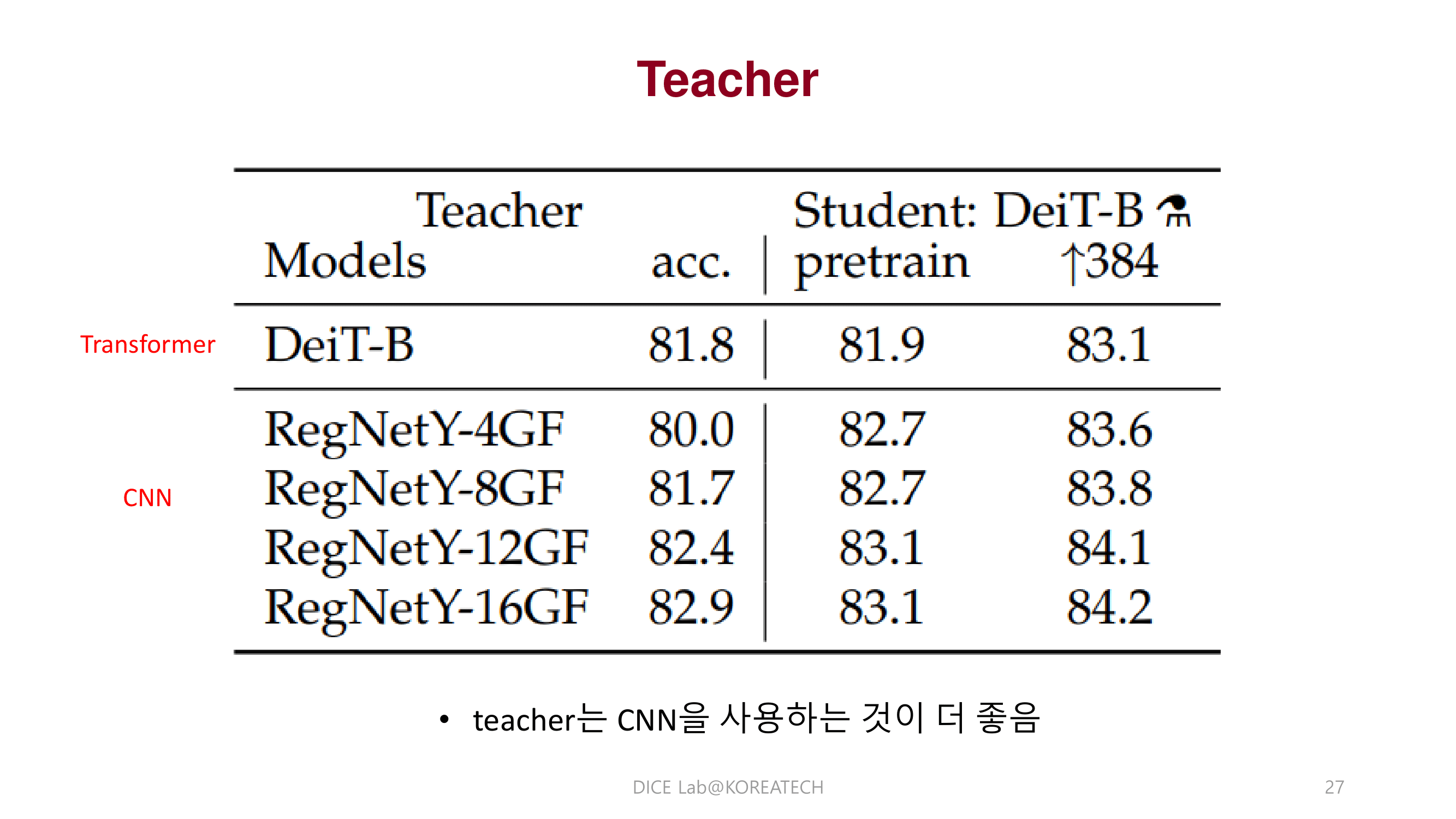
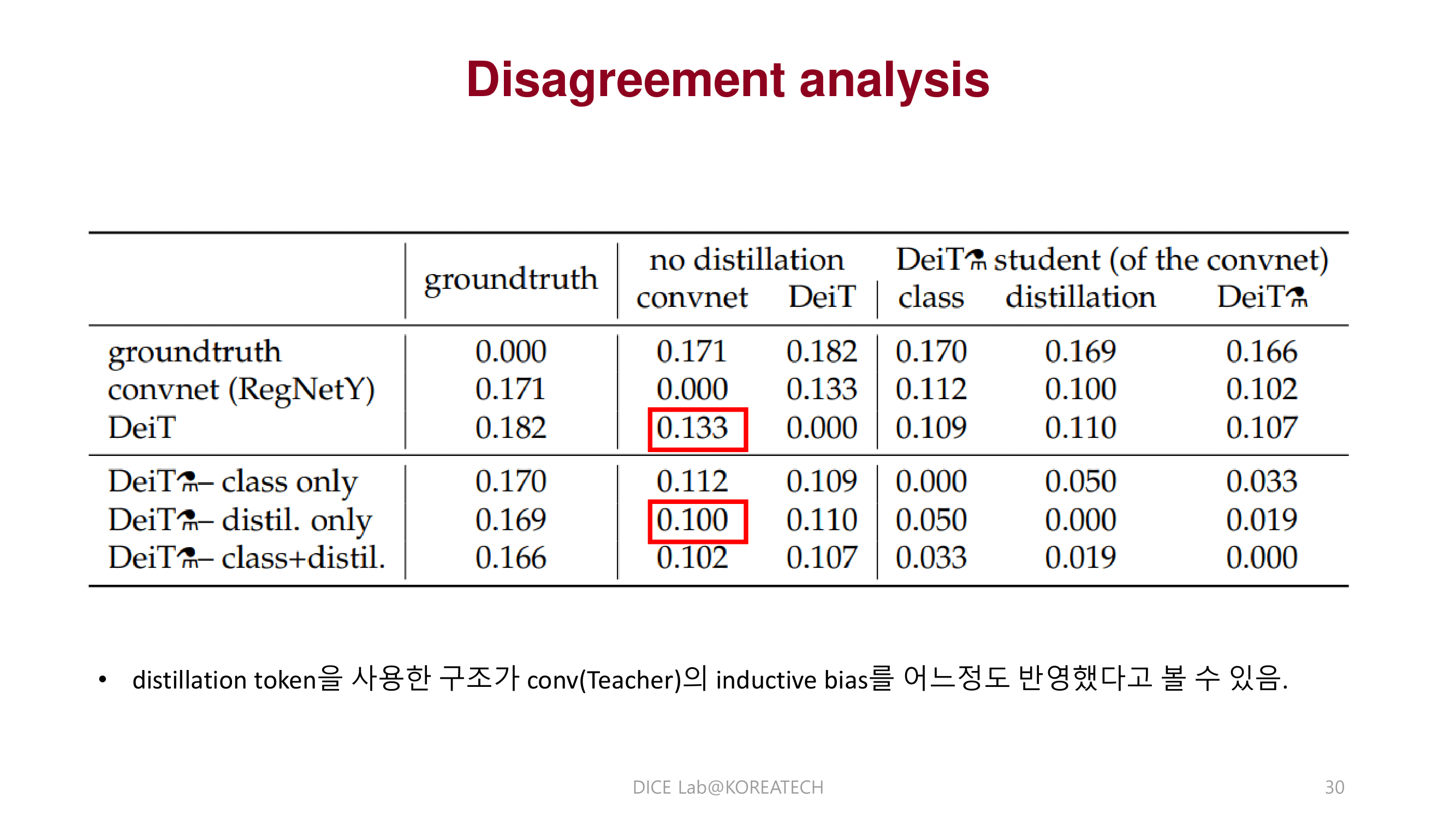
DeiT에서 제안한 distillation 방법이 Teacher가 CNN일때 inductive bias를 어느정도 학습해 성능을 더 끌어 올릴 수 있다는 것을 보여줌.
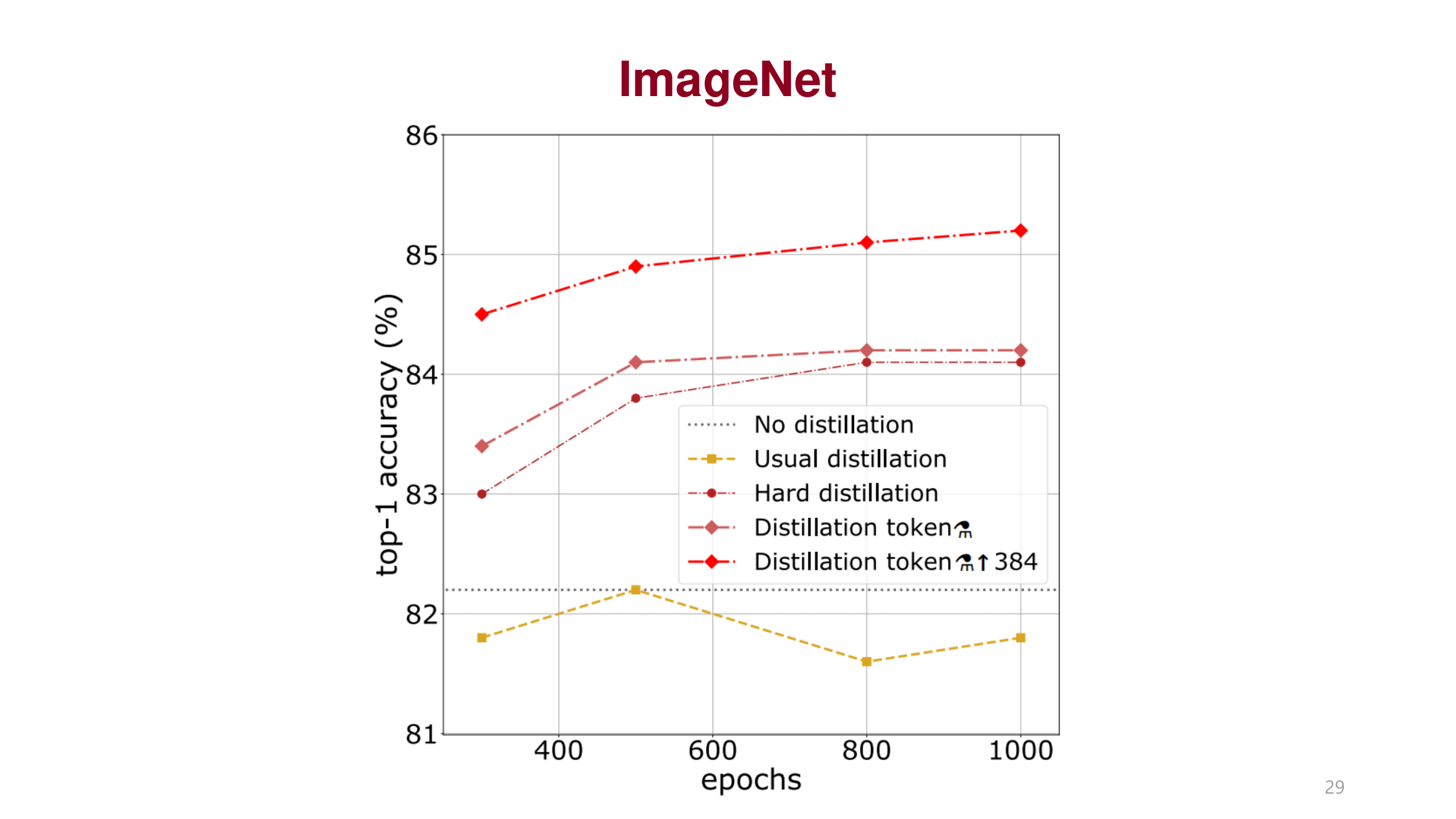
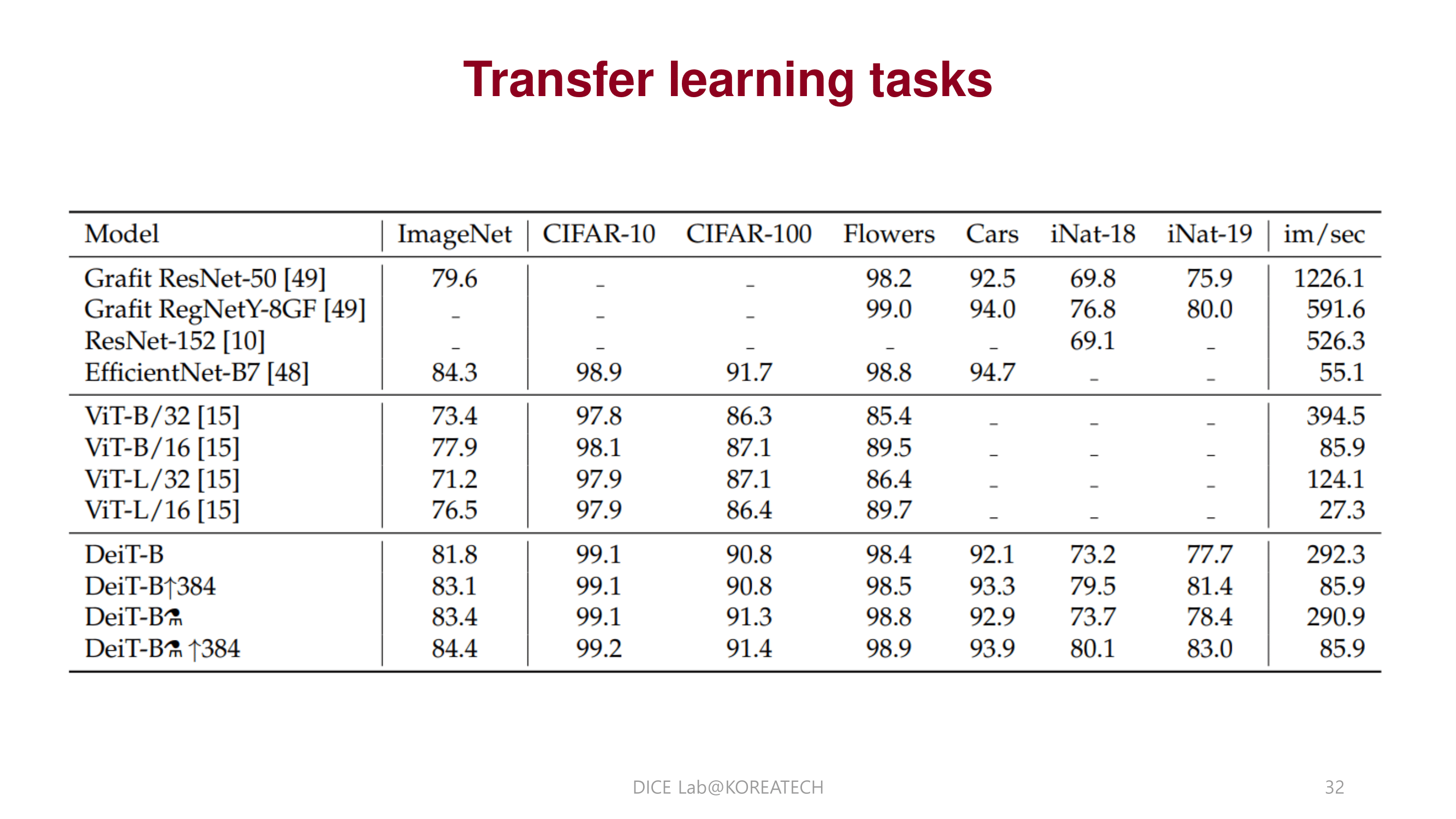
ImageNet에서 pretrain된 모델이 다른 데이터 셋 task에서도 좋은 성능을 도출함.
transformer를 image classification에서 비교적 가볍게 pretrain 가능하다는 것이 놀라웠다.
Knowledge Distillation 기법을 transformer안에 단순히 하나의 토큰으로 녹여낸 점이 인상적이었다.
Transformer를 실용적 pretrain 하기 위해서는 Knowledge Distillation 기법이 핵심적인 역할을 하기때문에 앞으로 CV에서 Transformer에 KD를 효율적이게 사용할 수 있게 하는 연구가 활발해질 것 같다는 느낌을 받았다.
Reference
This post is licensed under CC BY 4.0 by the author.