Paper Review. Momentum Contrast for Unsupervised Visual Representation Learning@CVPR’ 2020
Abstract

Introduction


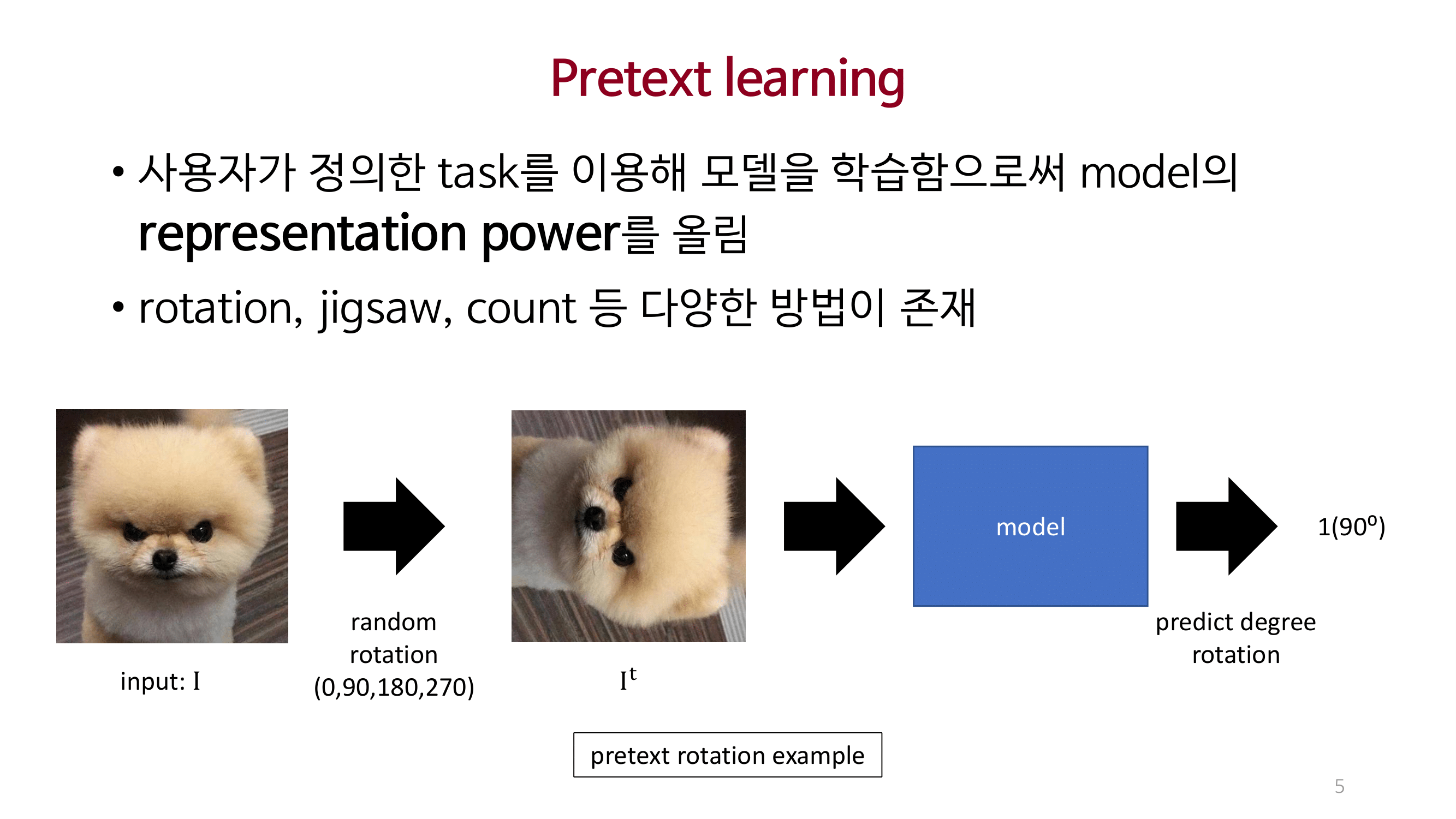


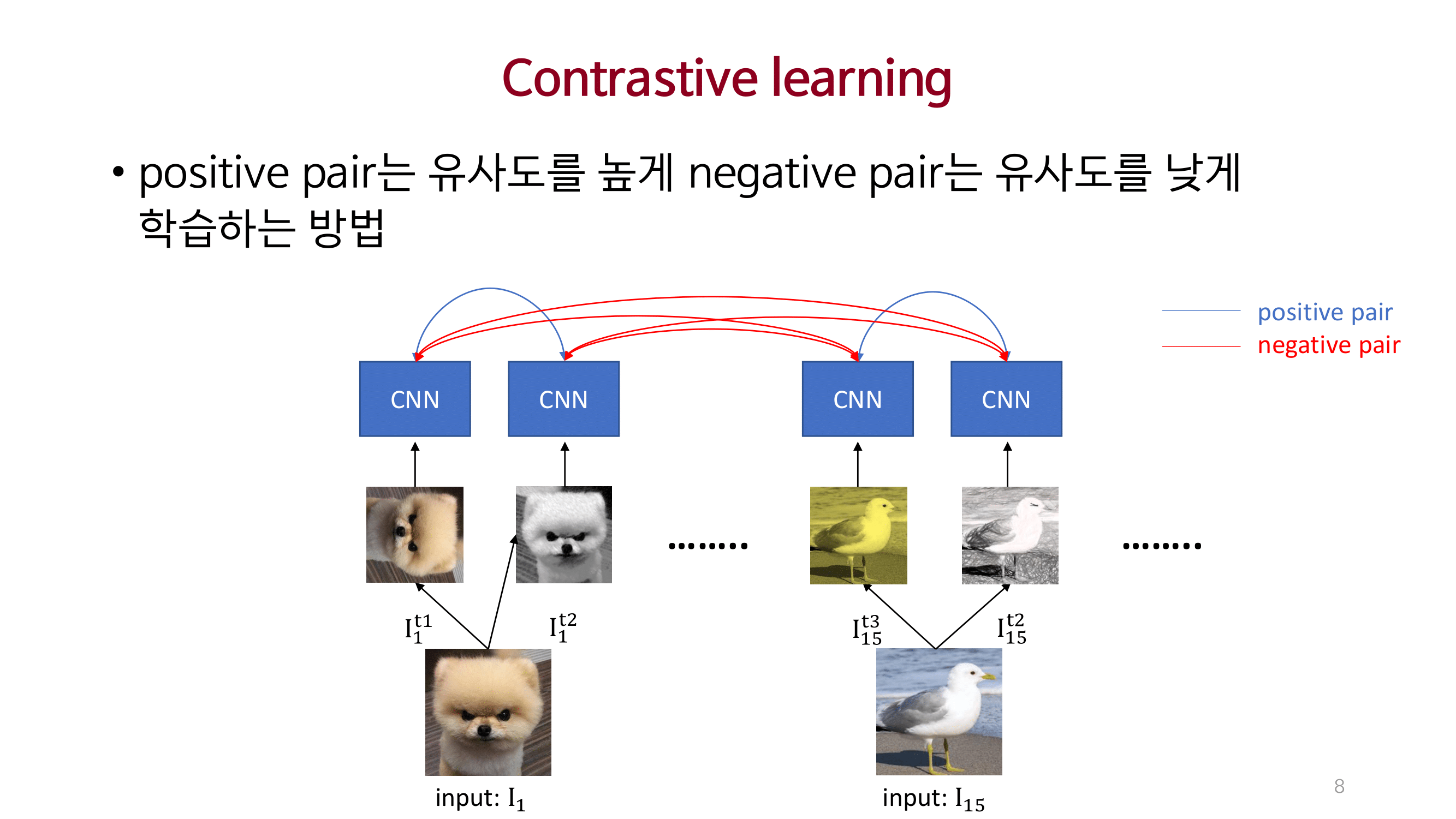
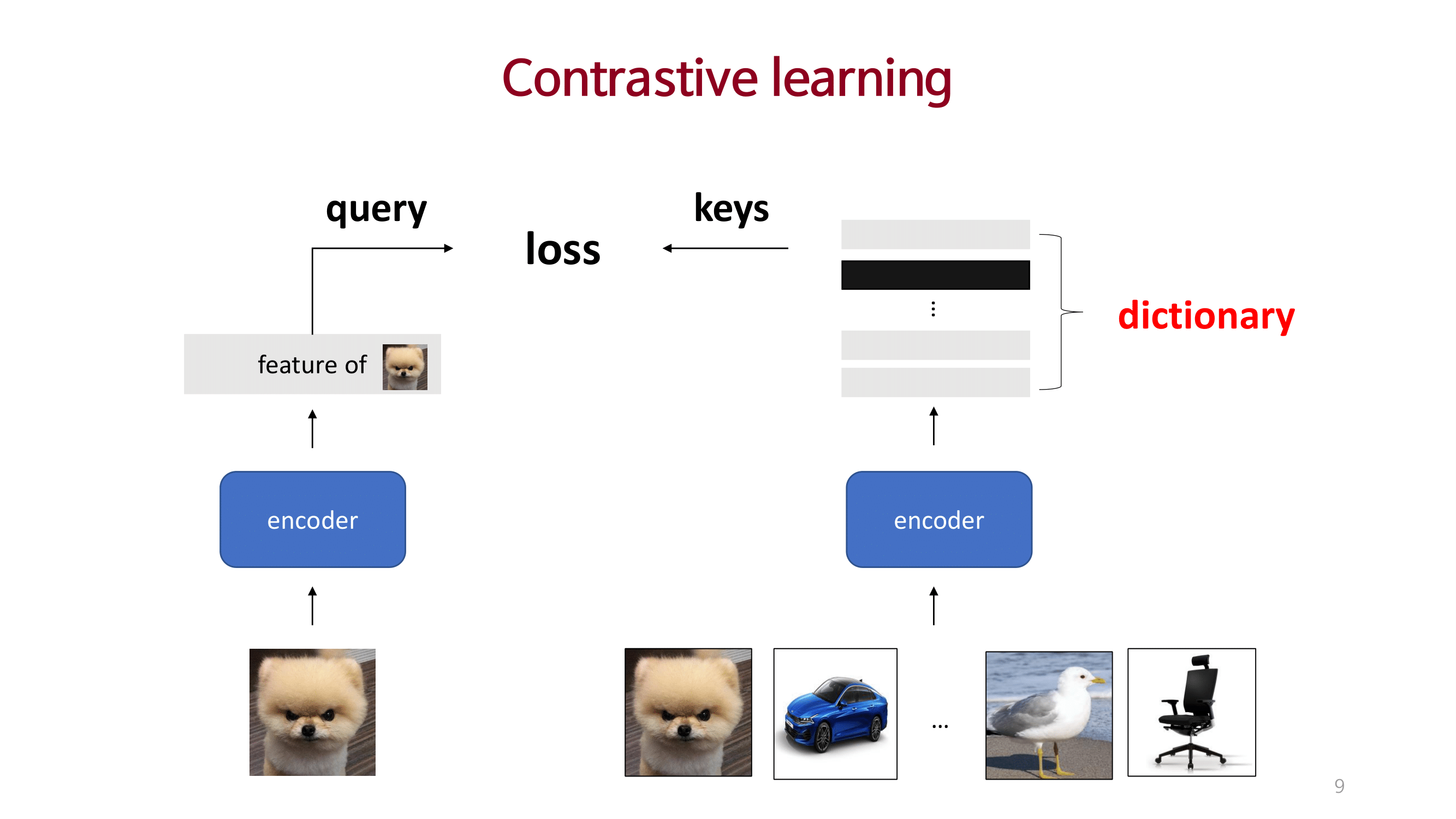
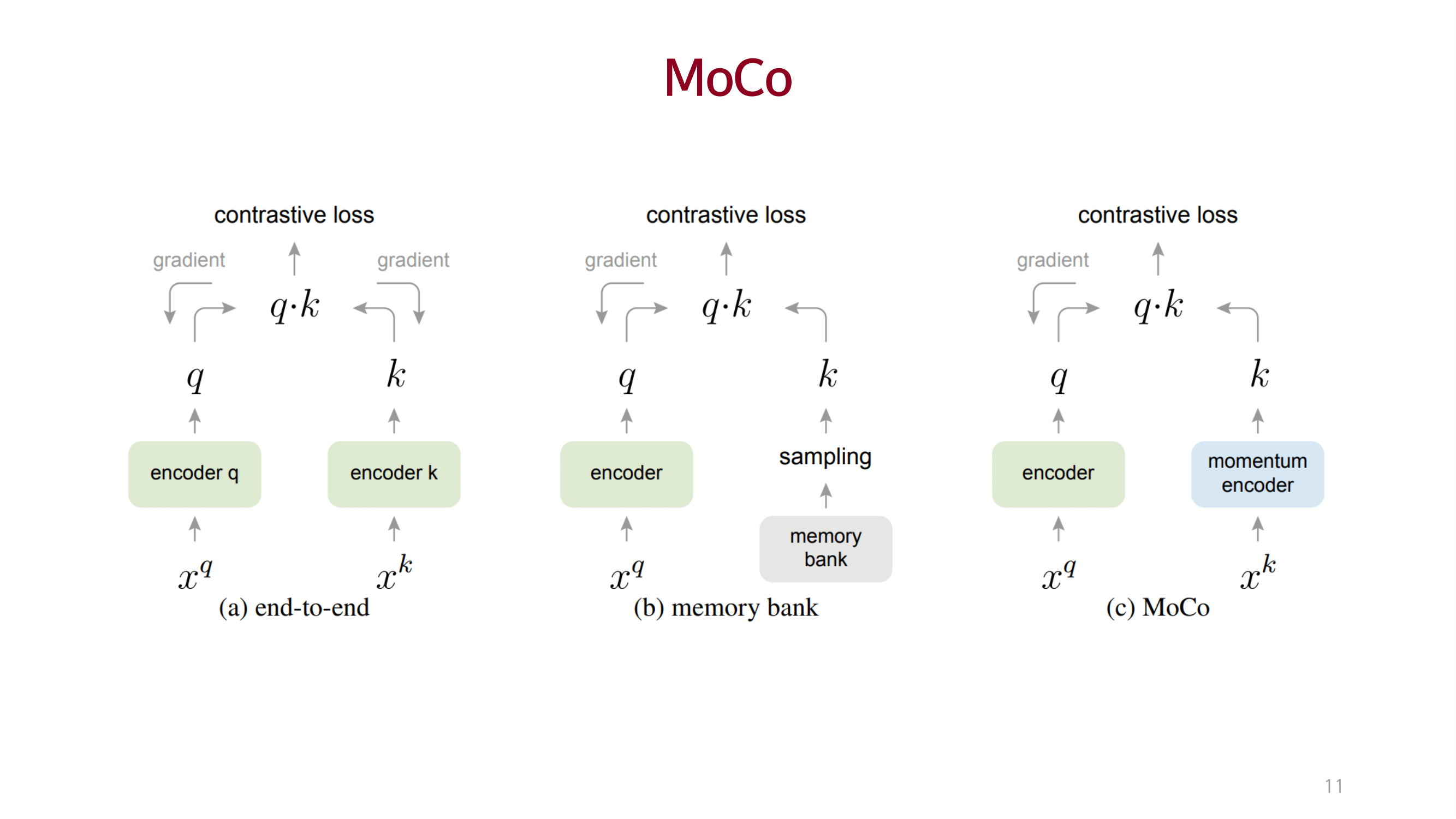
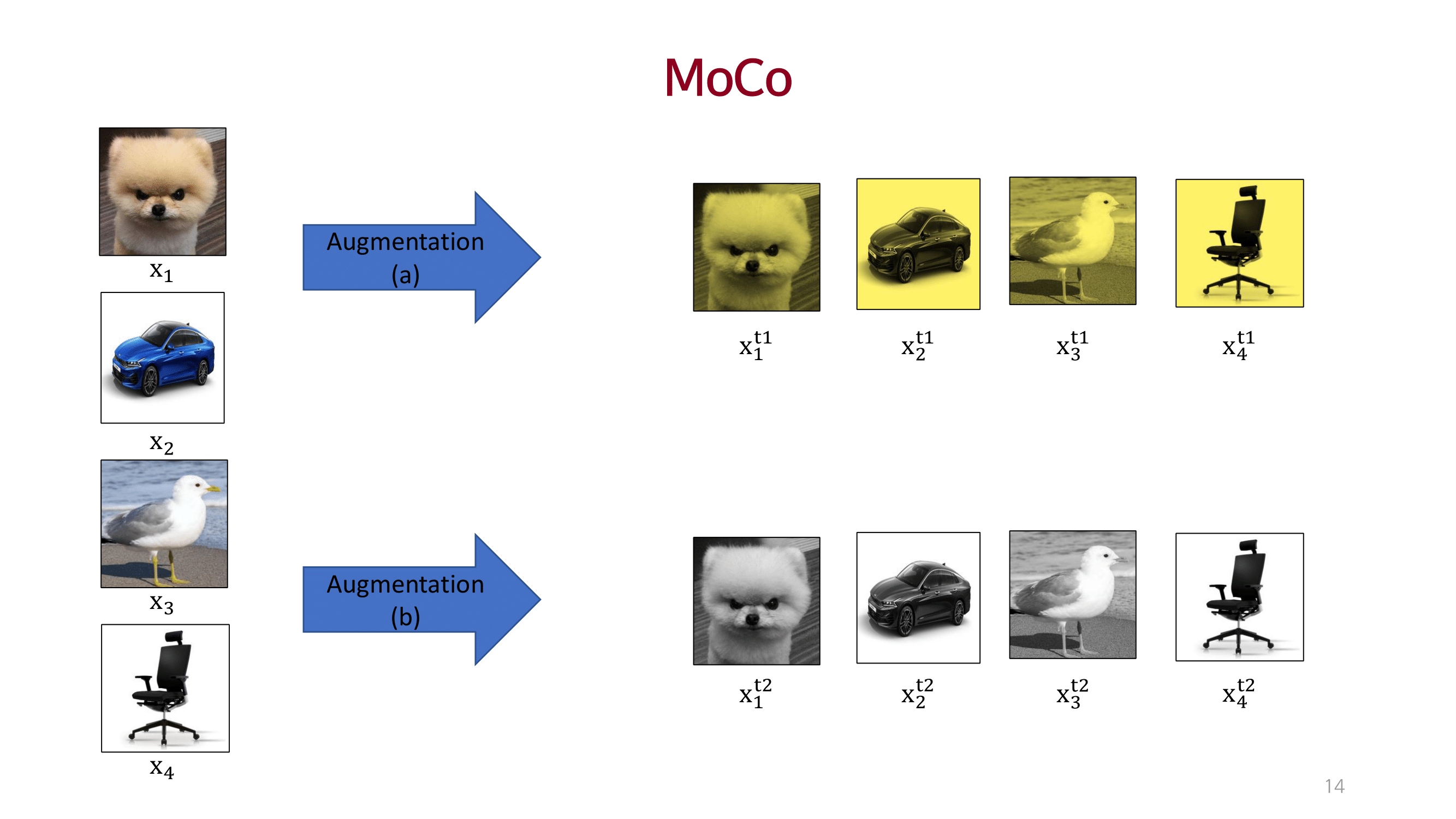
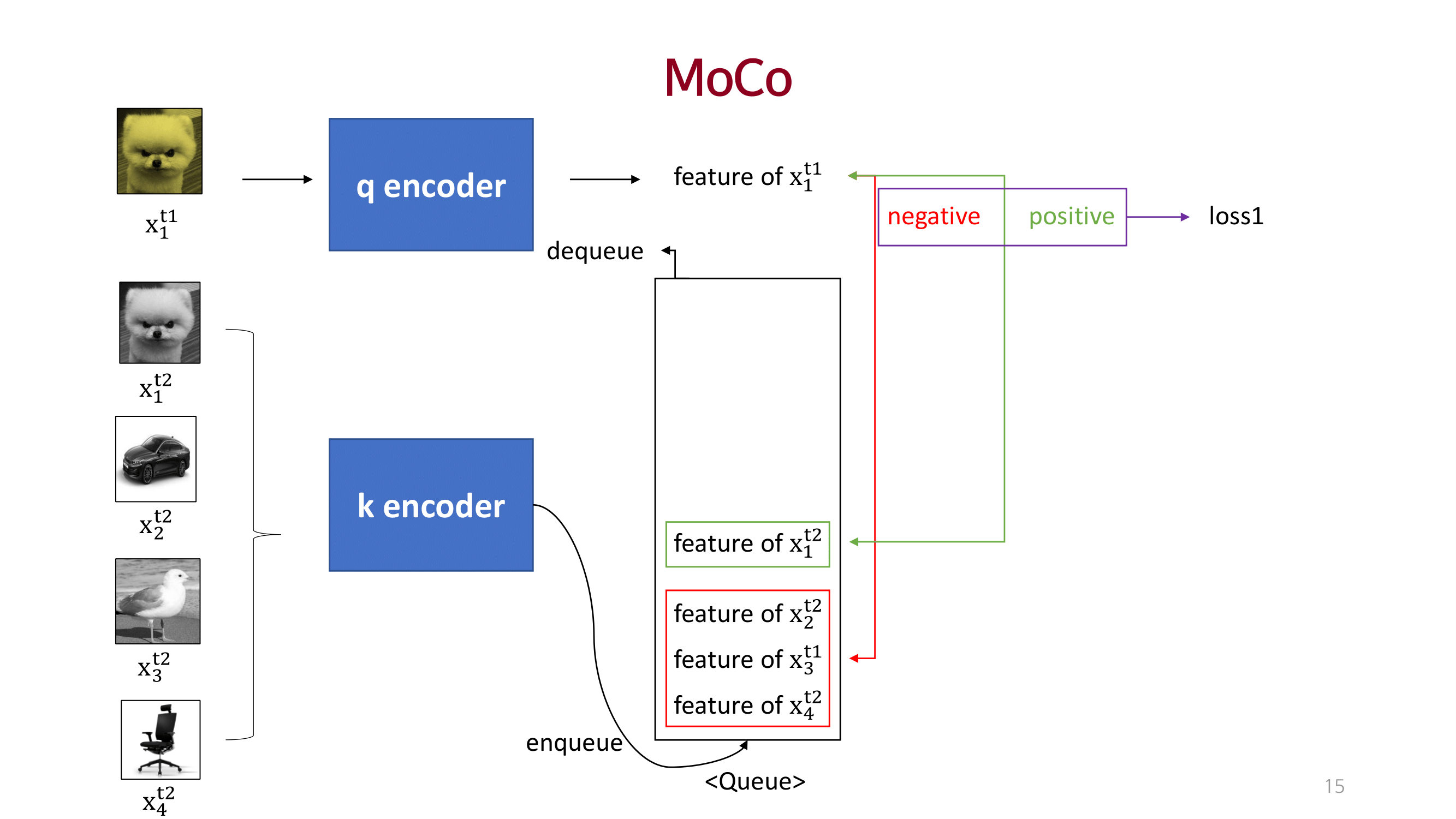
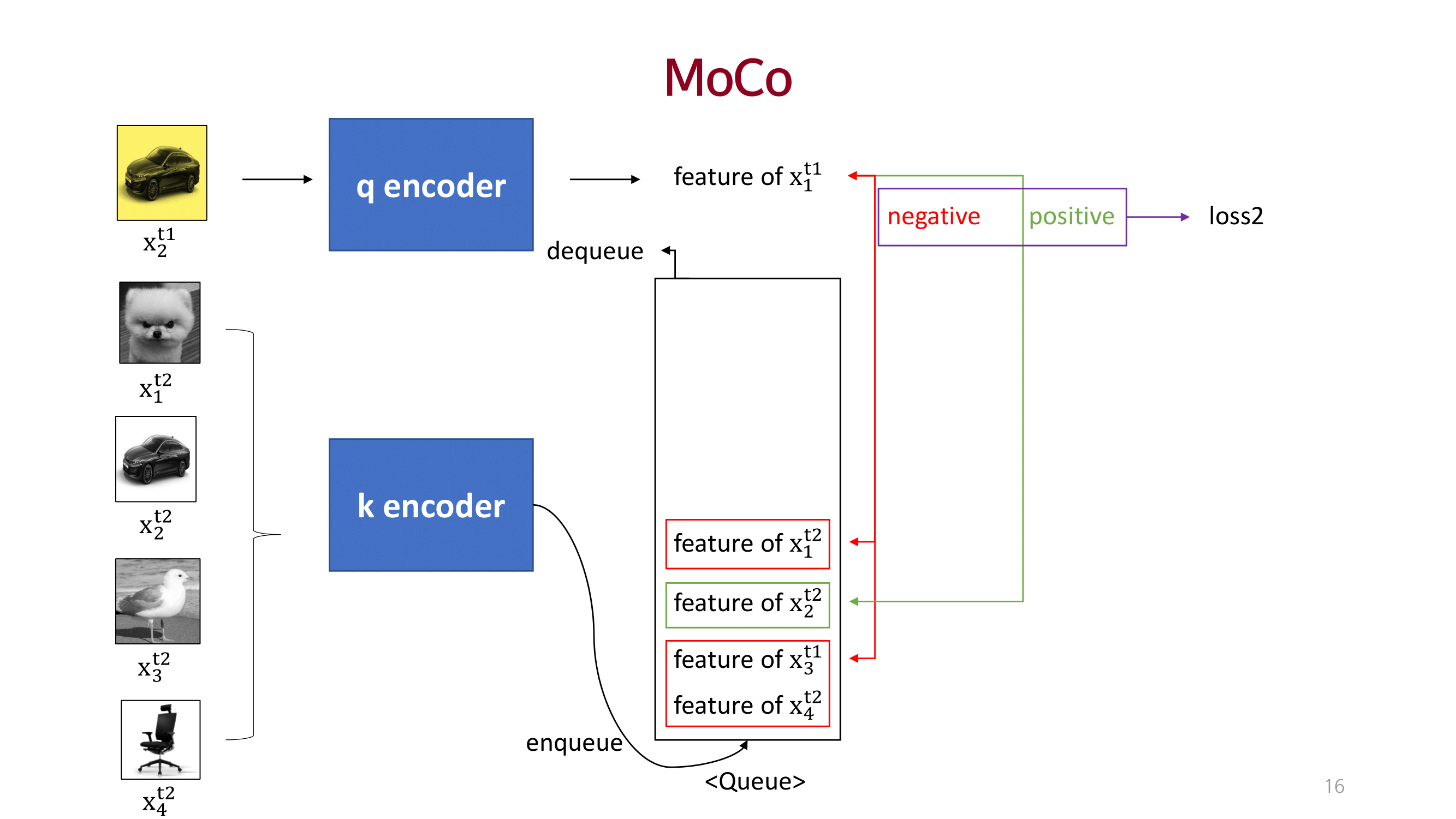
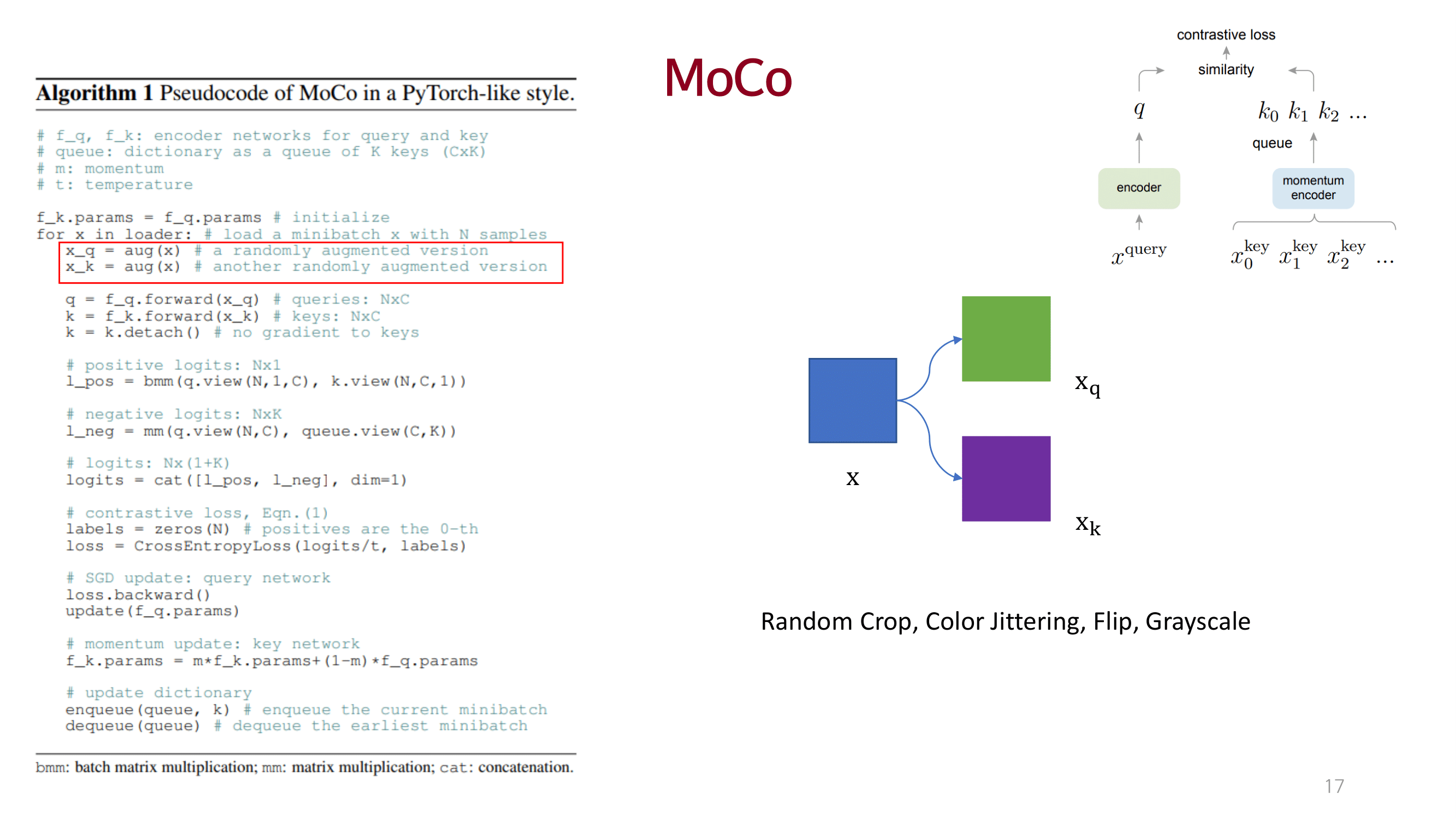
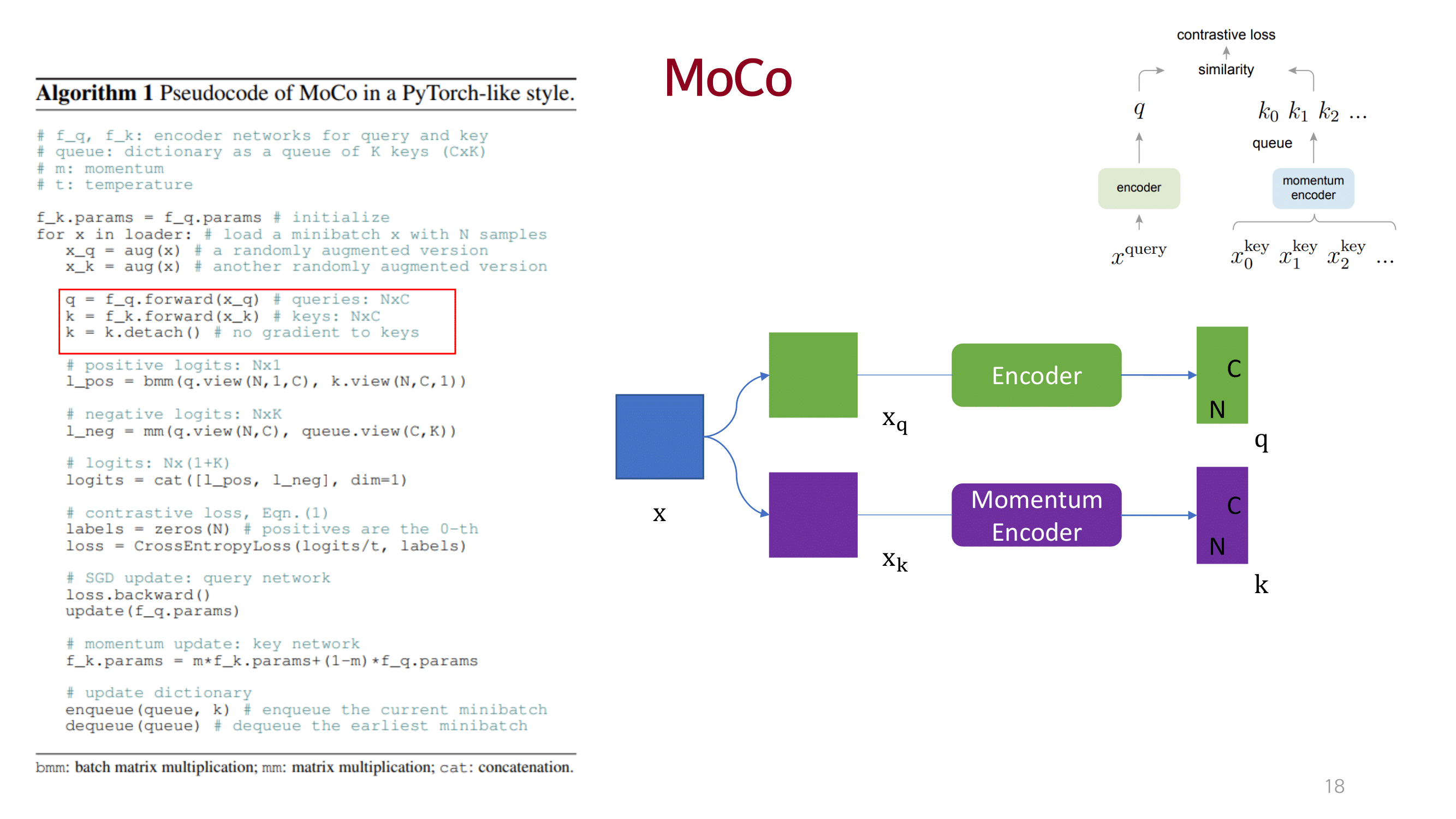
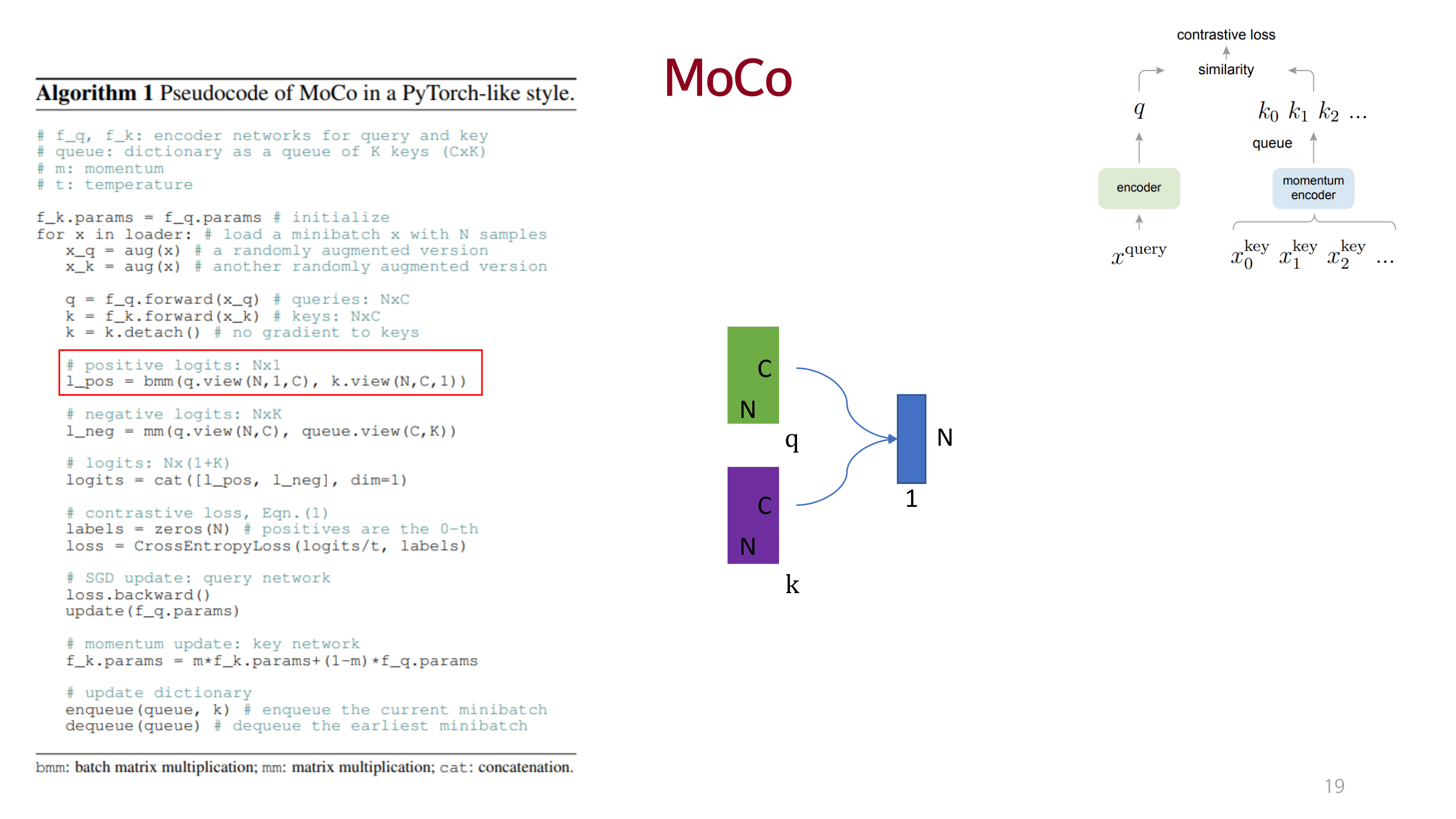
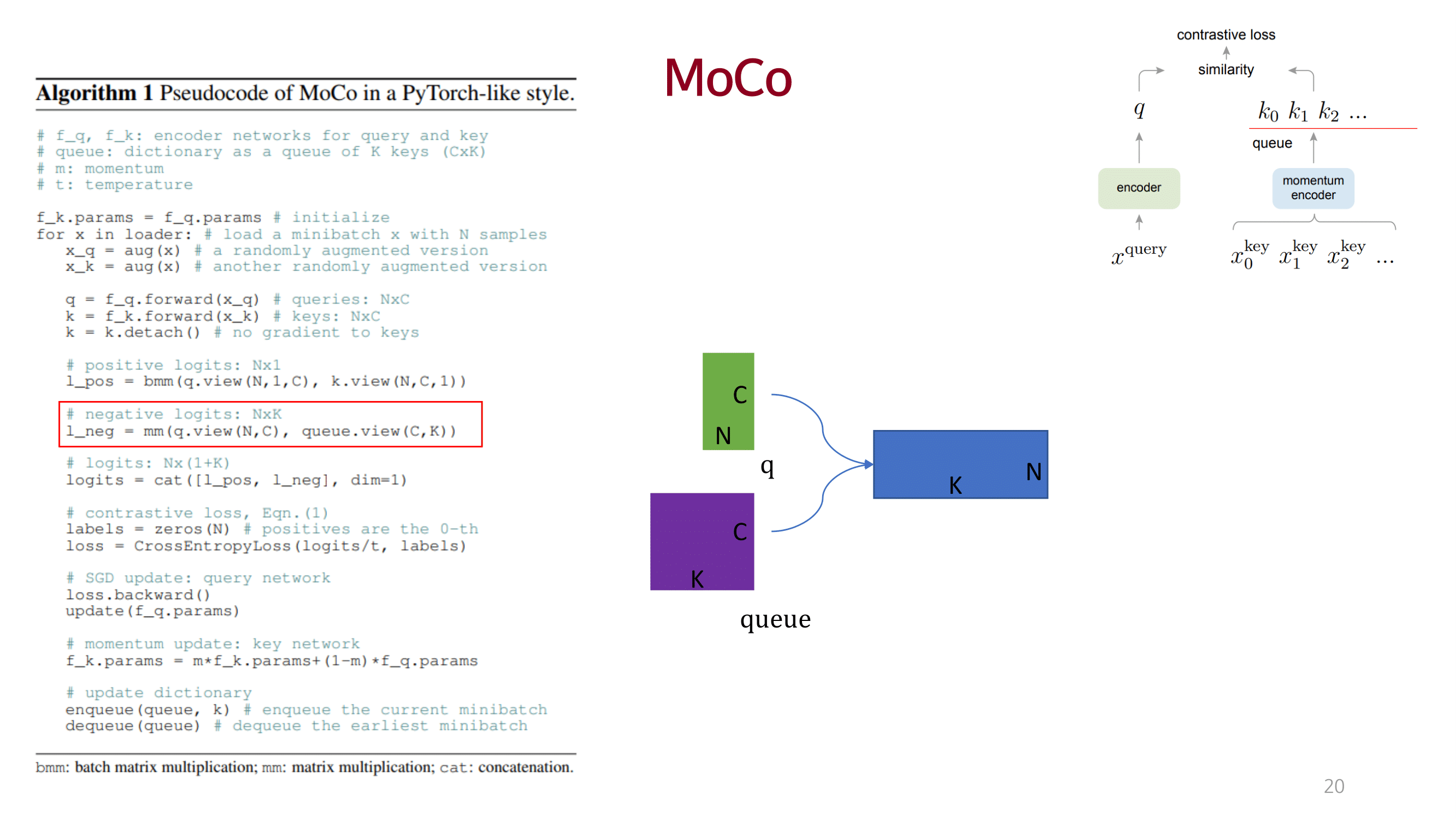
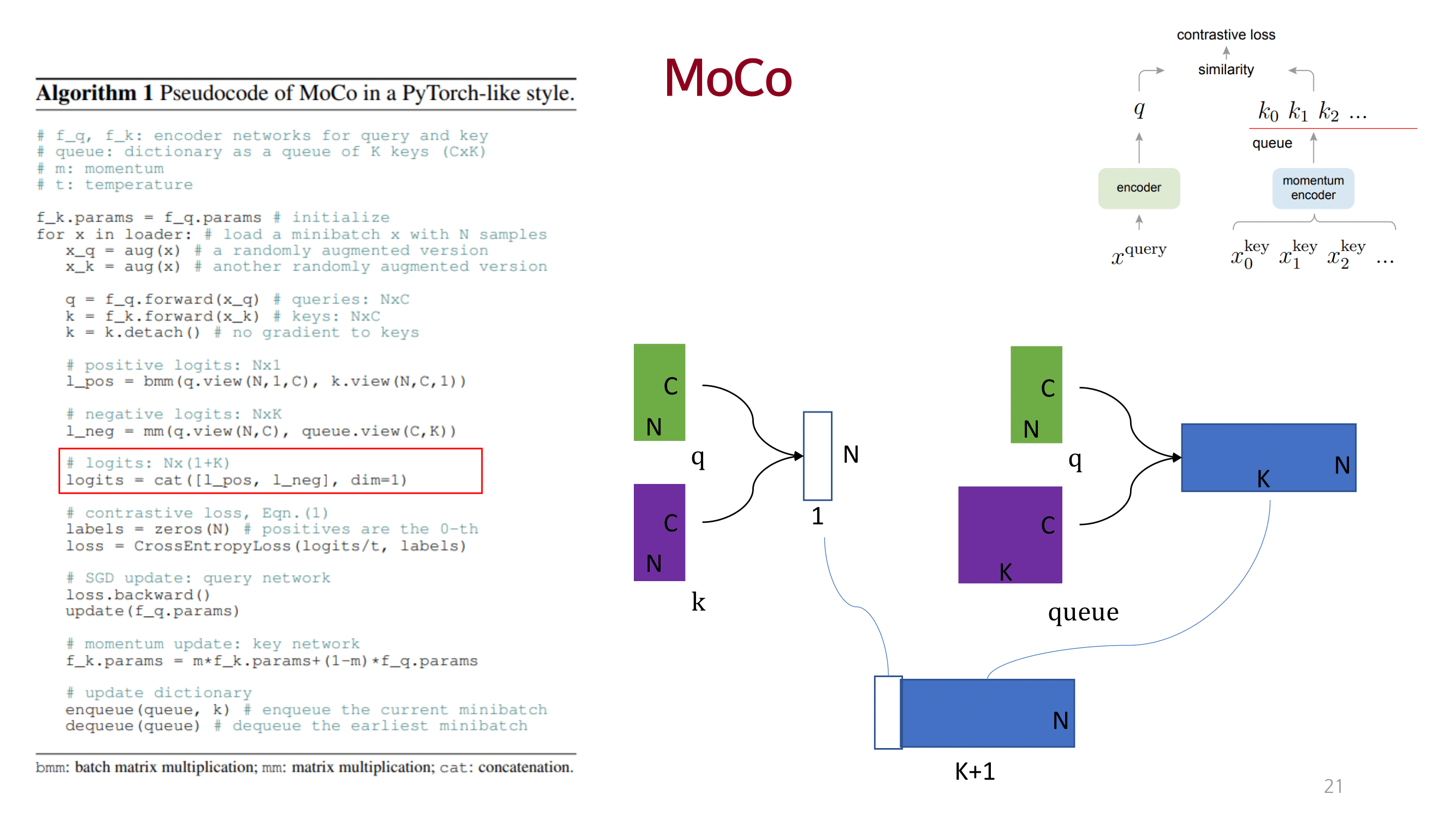
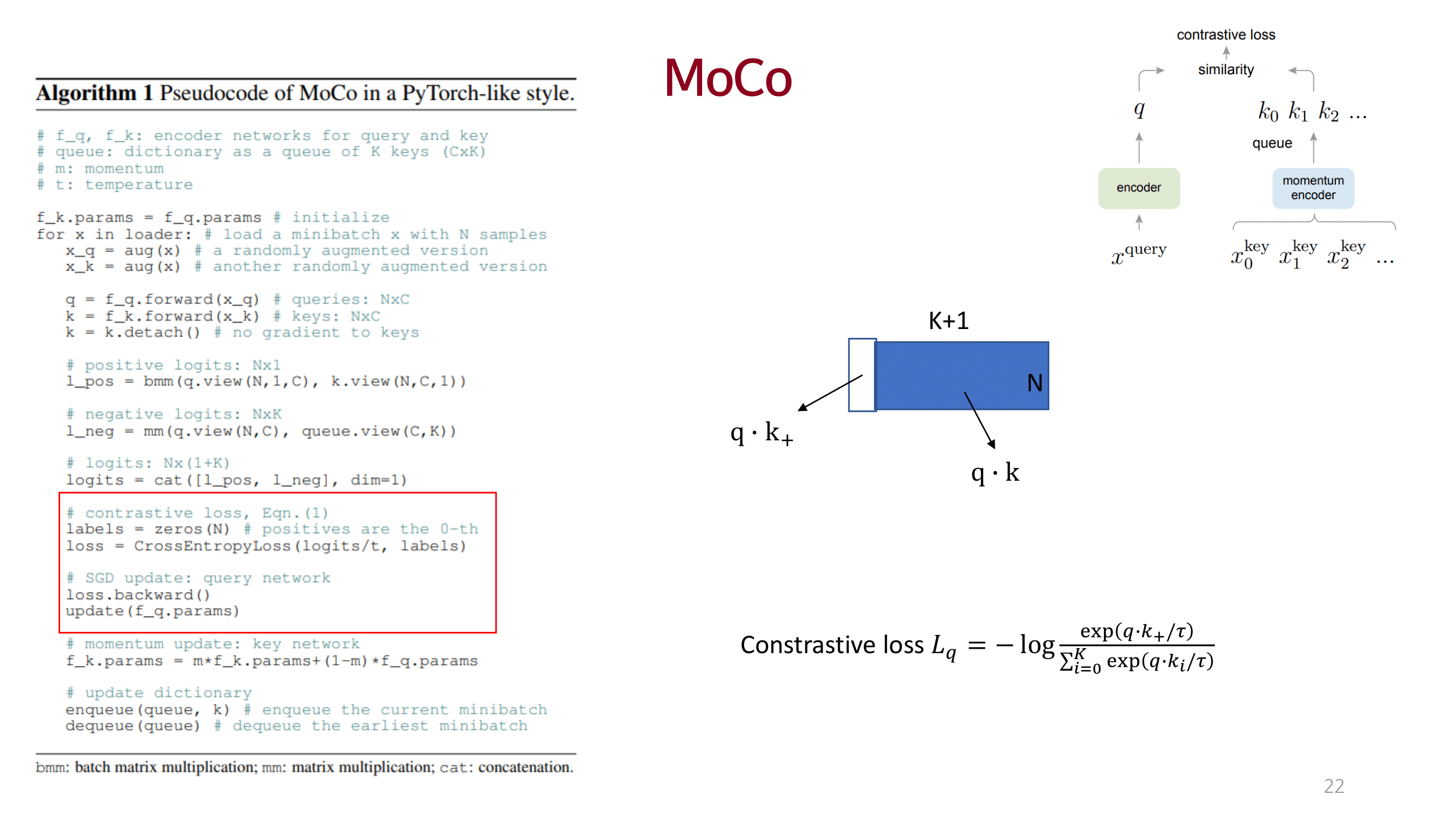
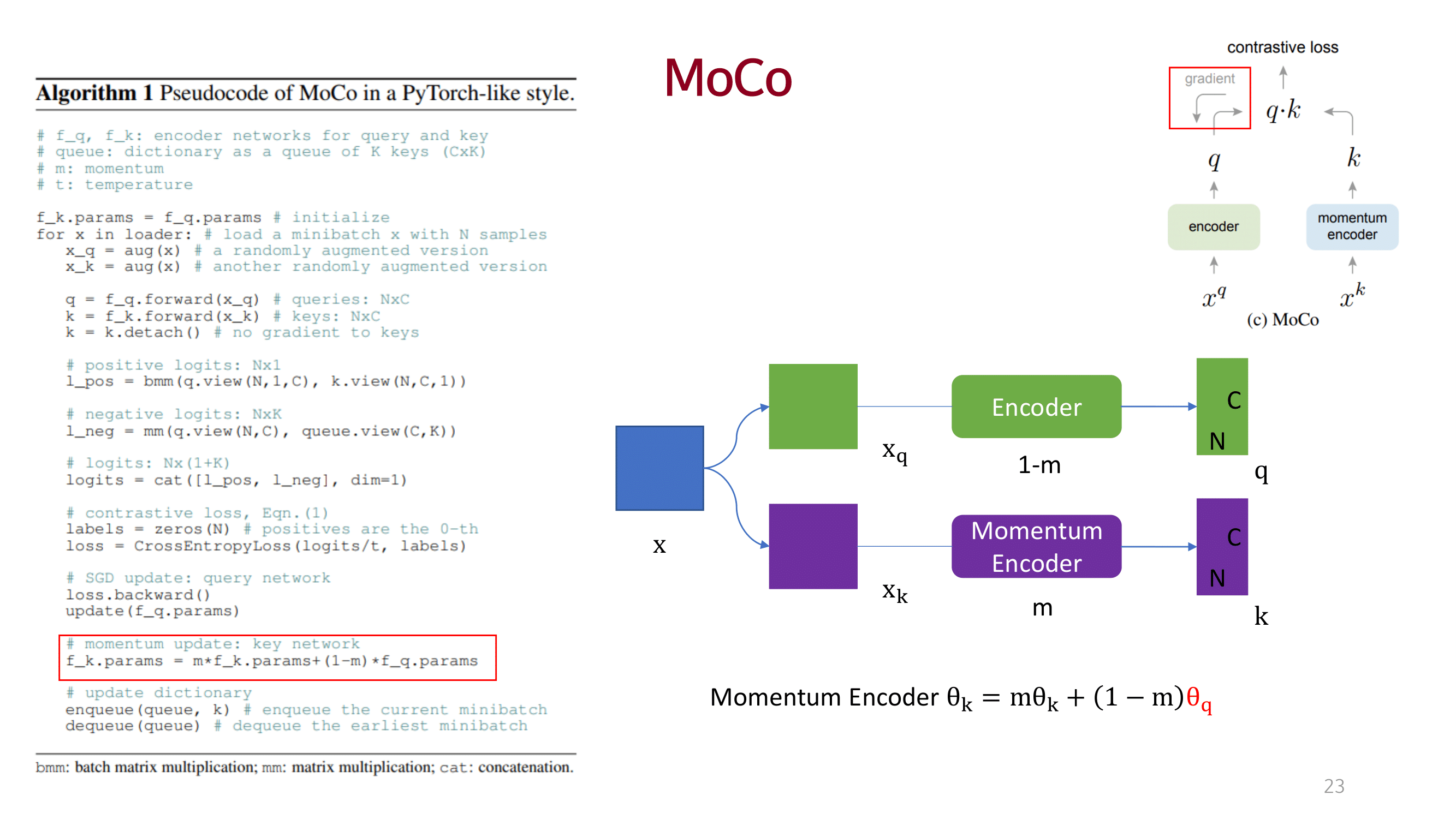
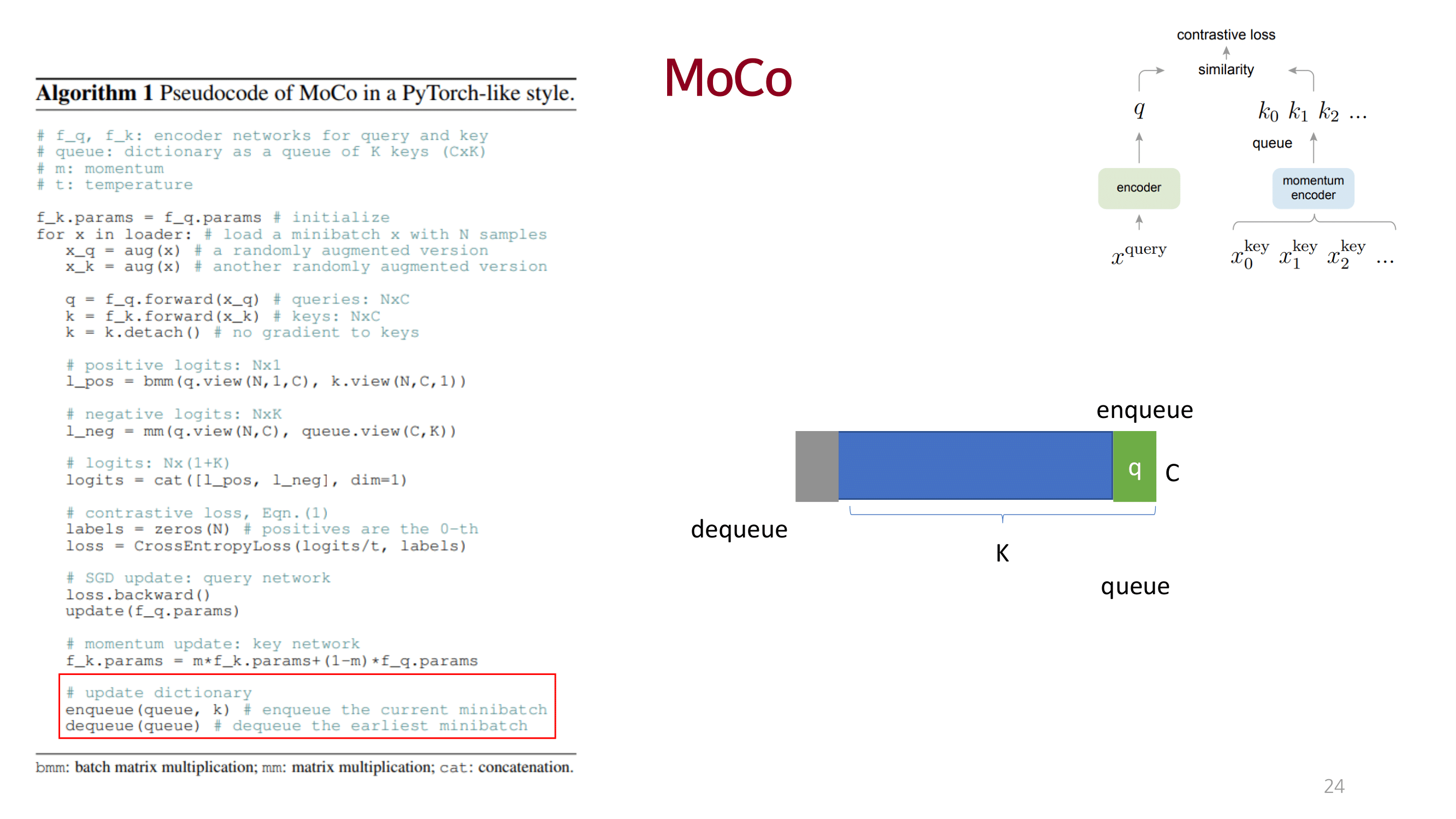
MOCO
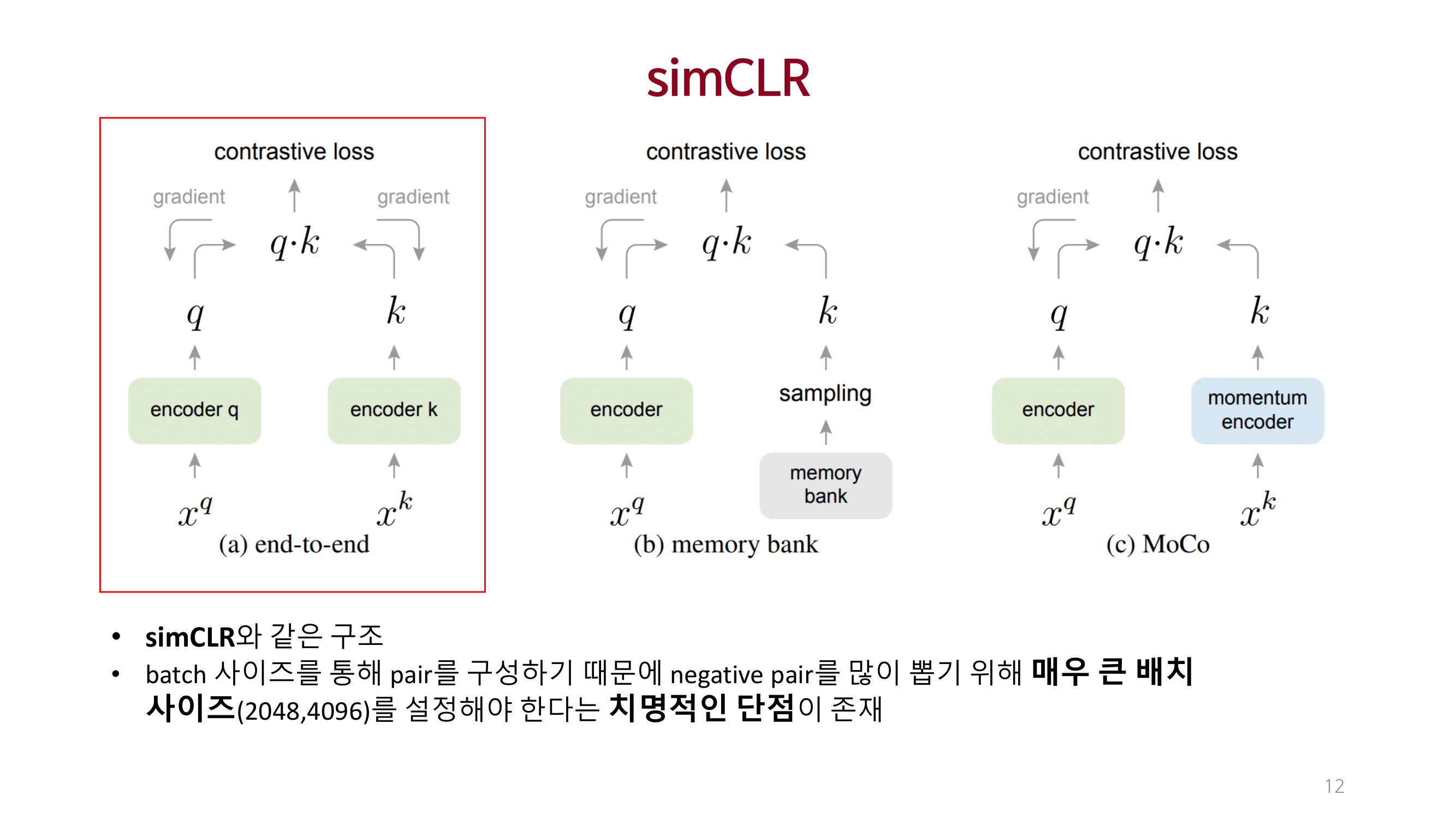
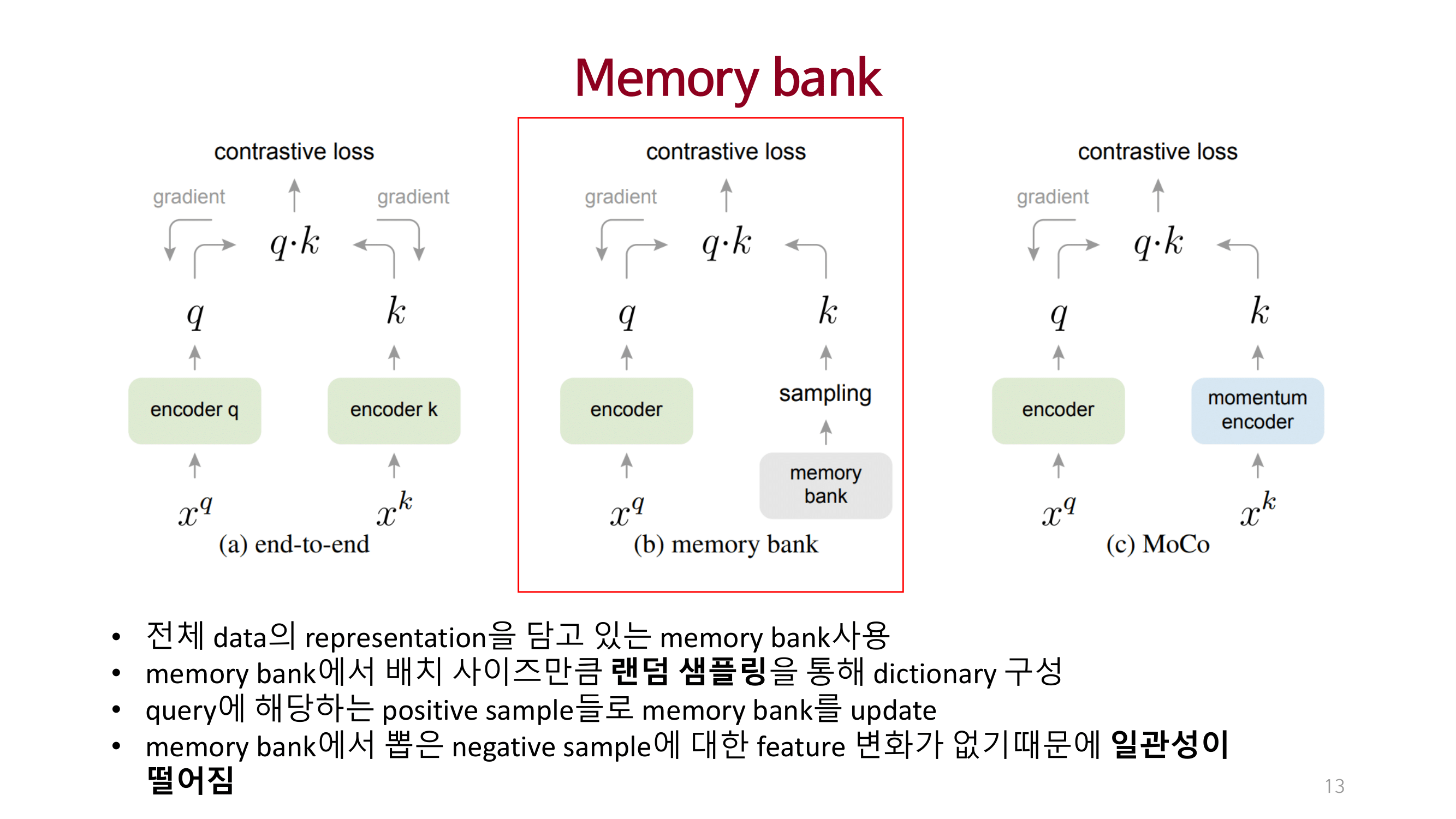
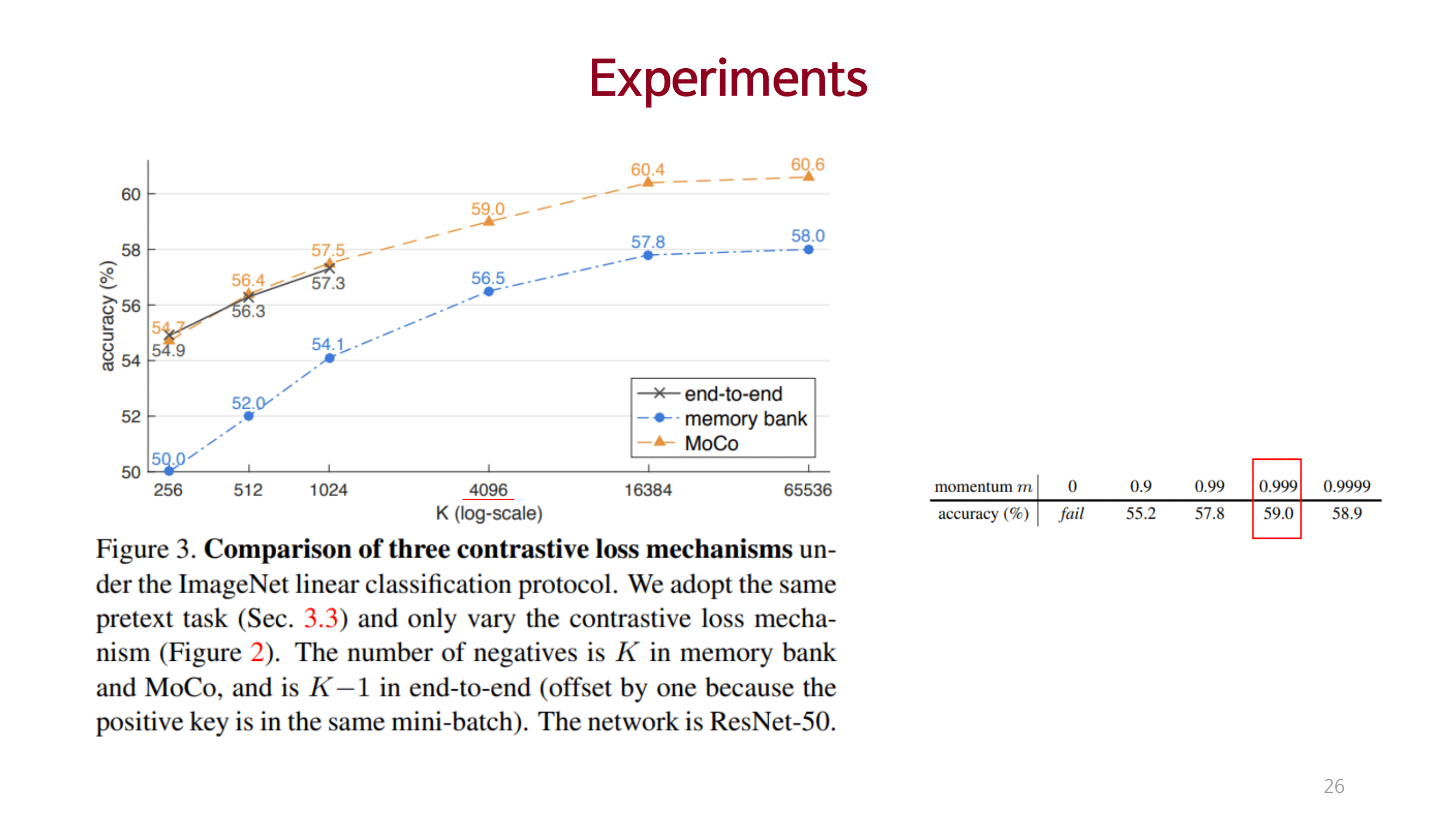
Experiments

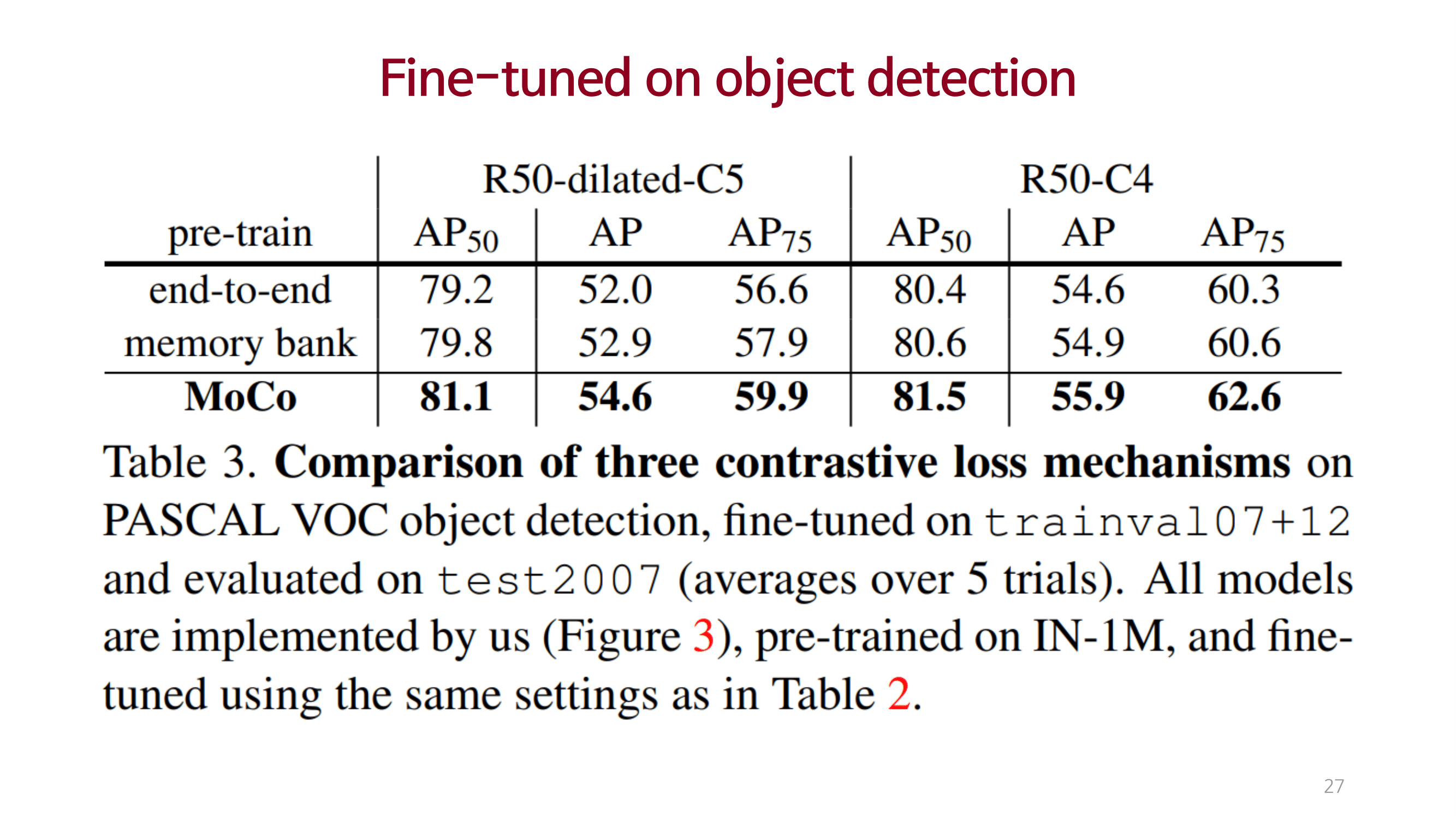
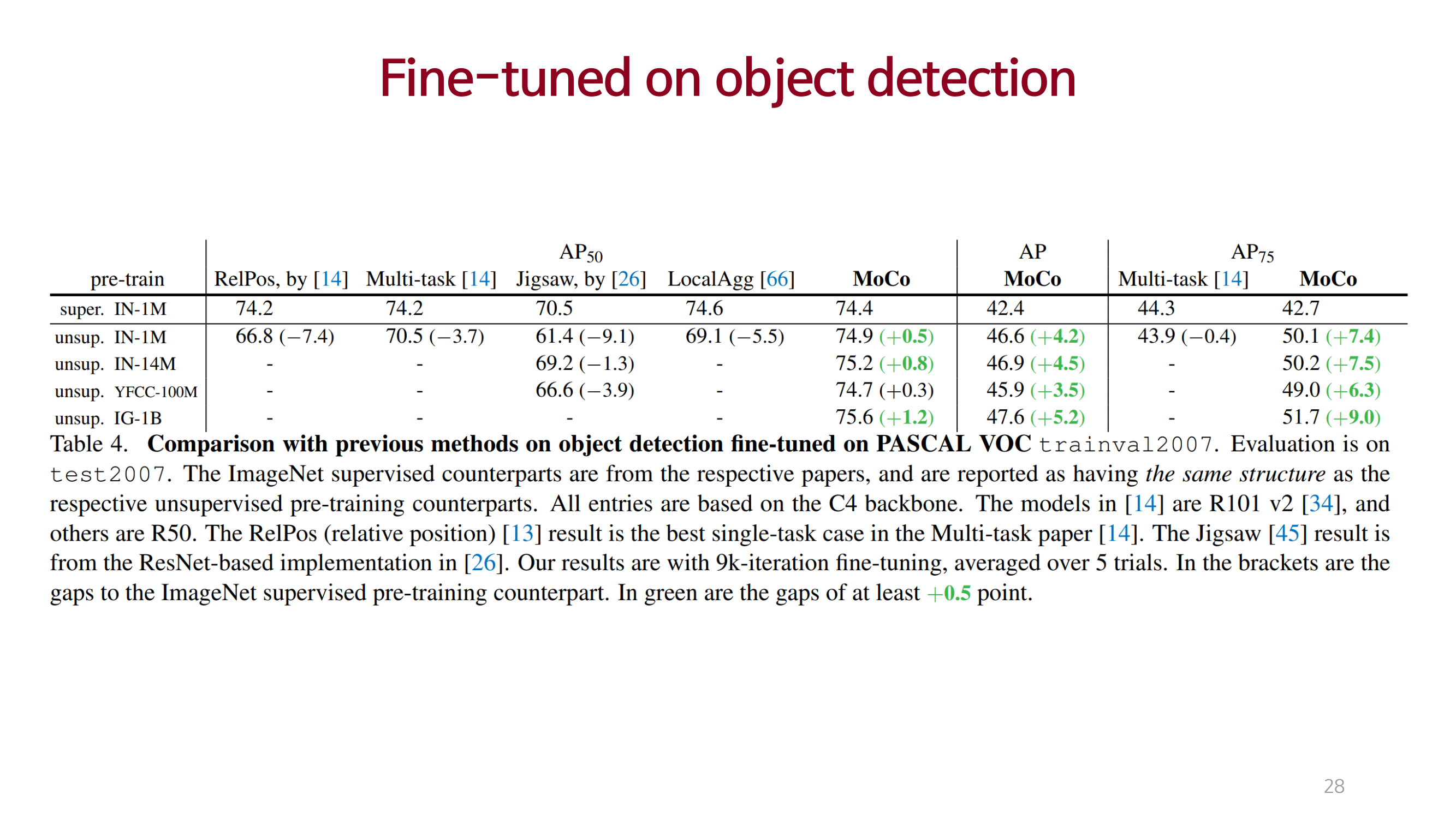
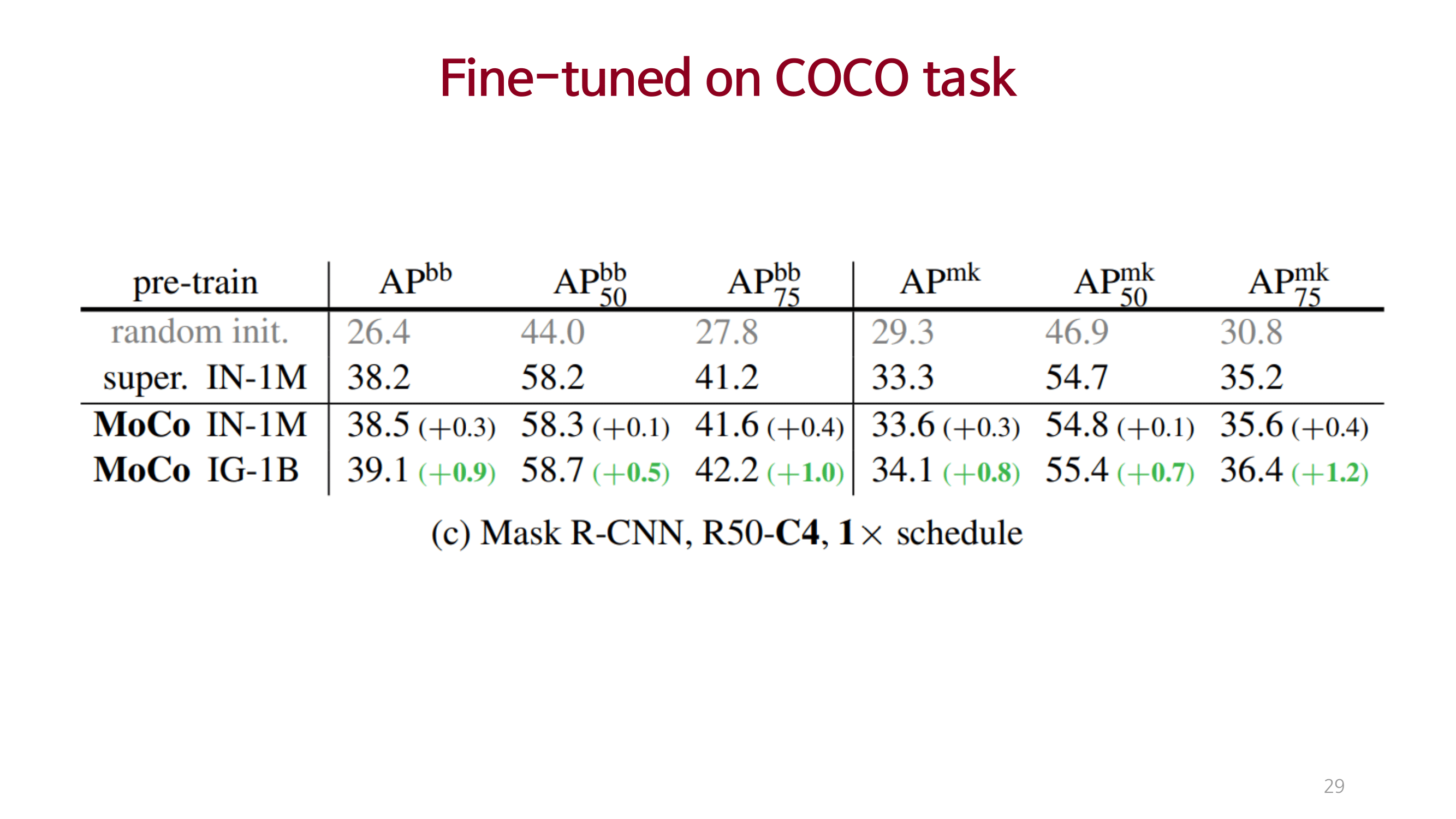
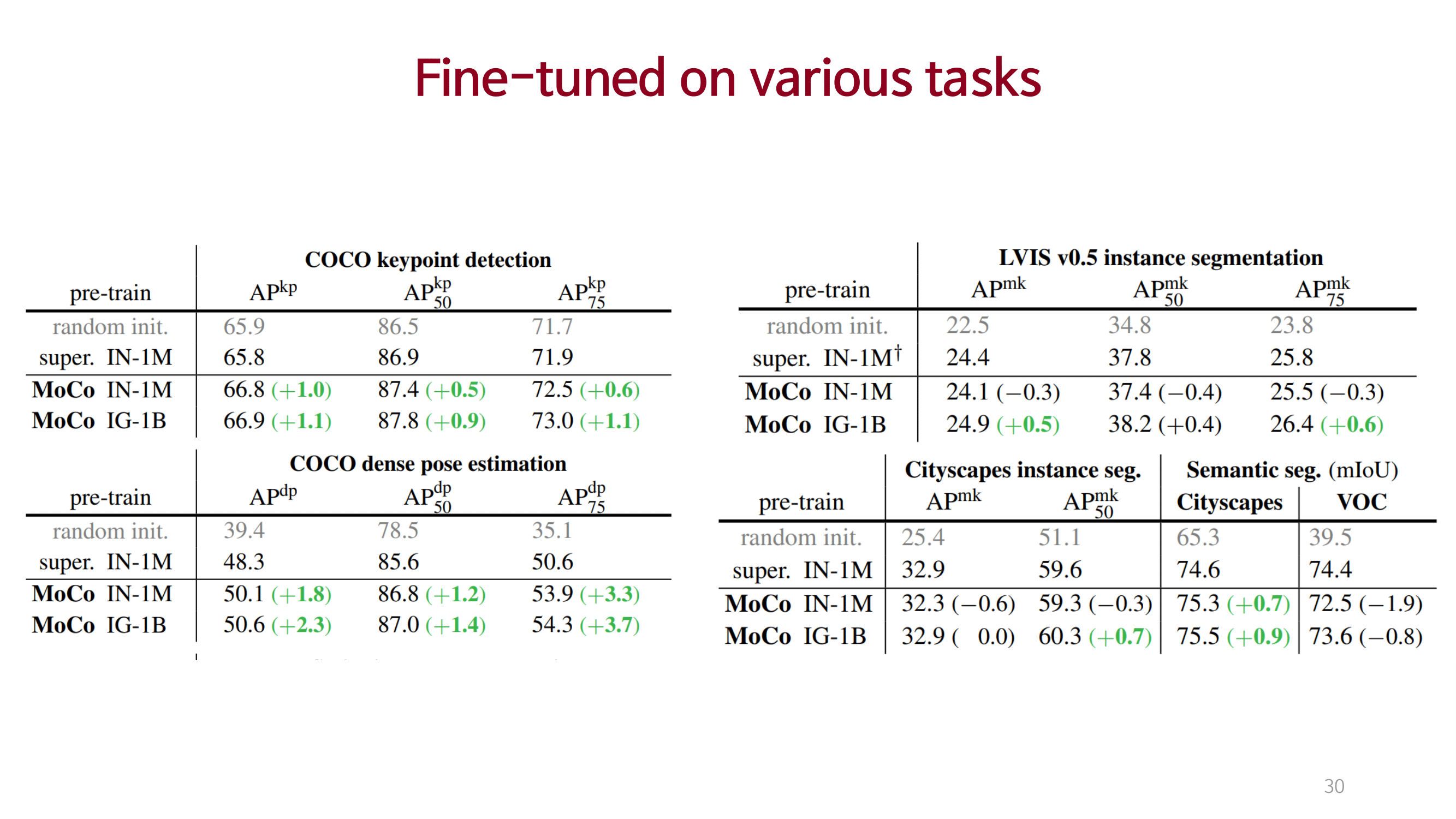
Conclusions & Reviews
큰 사이즈의 dictionary를 사용하여 충분한 양의 negative를 고려함으로써 성능을 끌어올림.
dictionary를 queue 개념으로 접근하고 momentum 방법을 이용해 consistency를 유지함.
transformer 구조에서도 self-supervised를 적용하면 좋을거 같다는 생각이 들었음.
augmentation이 중요하다고 생각이 되는데 augmentation에 따른 성능 차이가 없었던 점이 다소 아쉬웠음.
Reference
This post is licensed under CC BY 4.0 by the author.