Paper Review. An all-MLP Architecture for Vision@arXiv’2021
Abstract


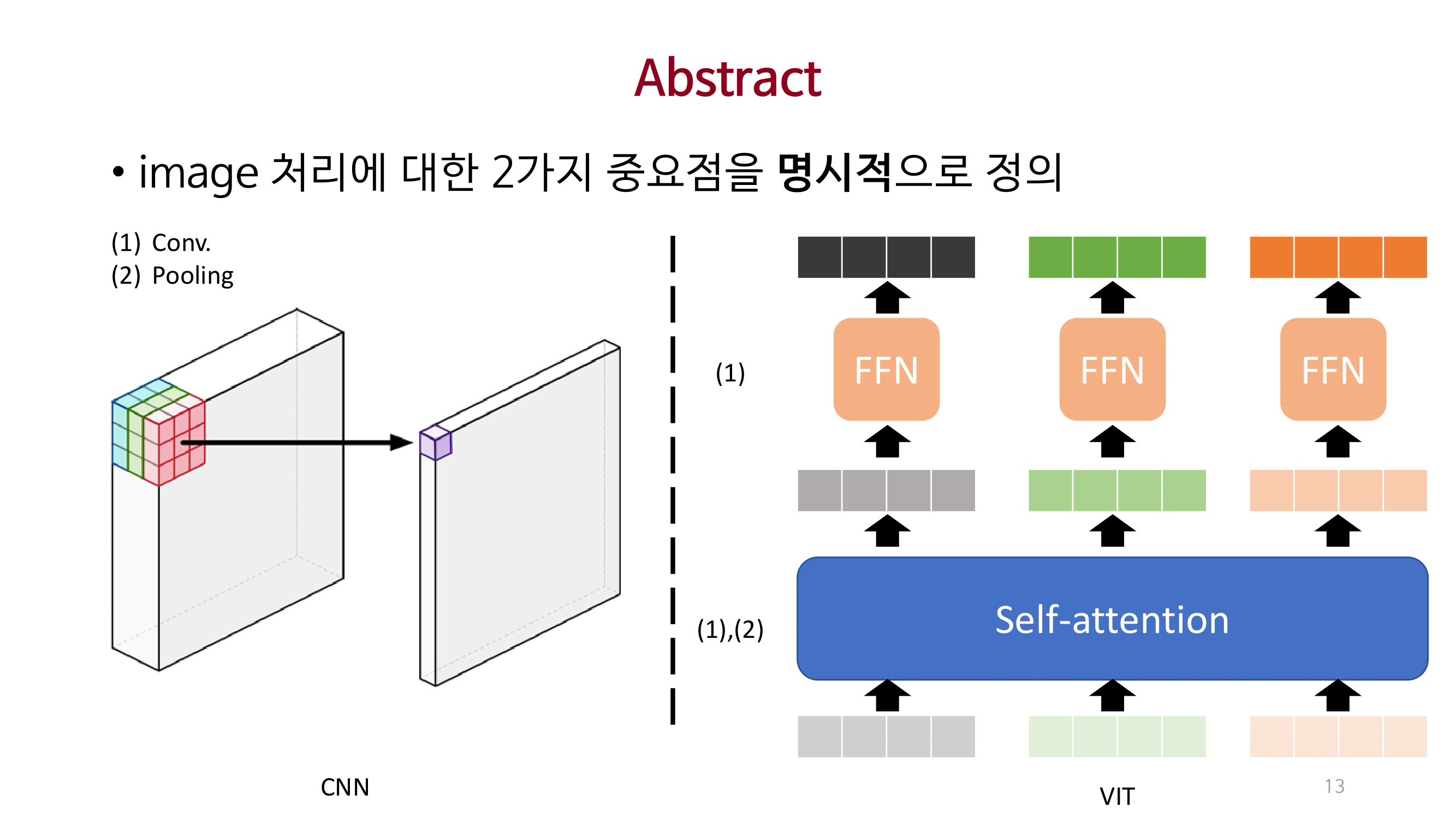
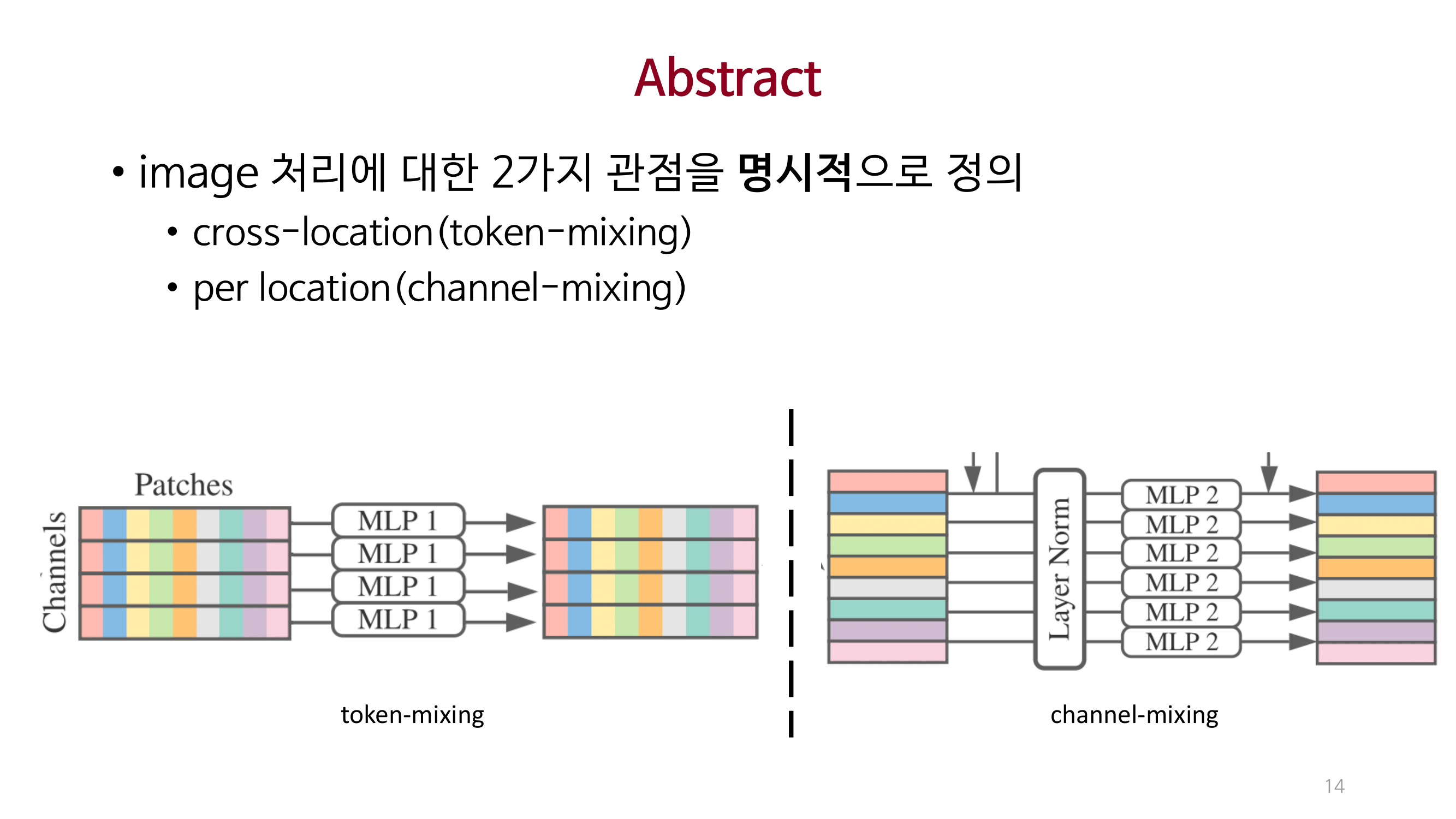
Introduction
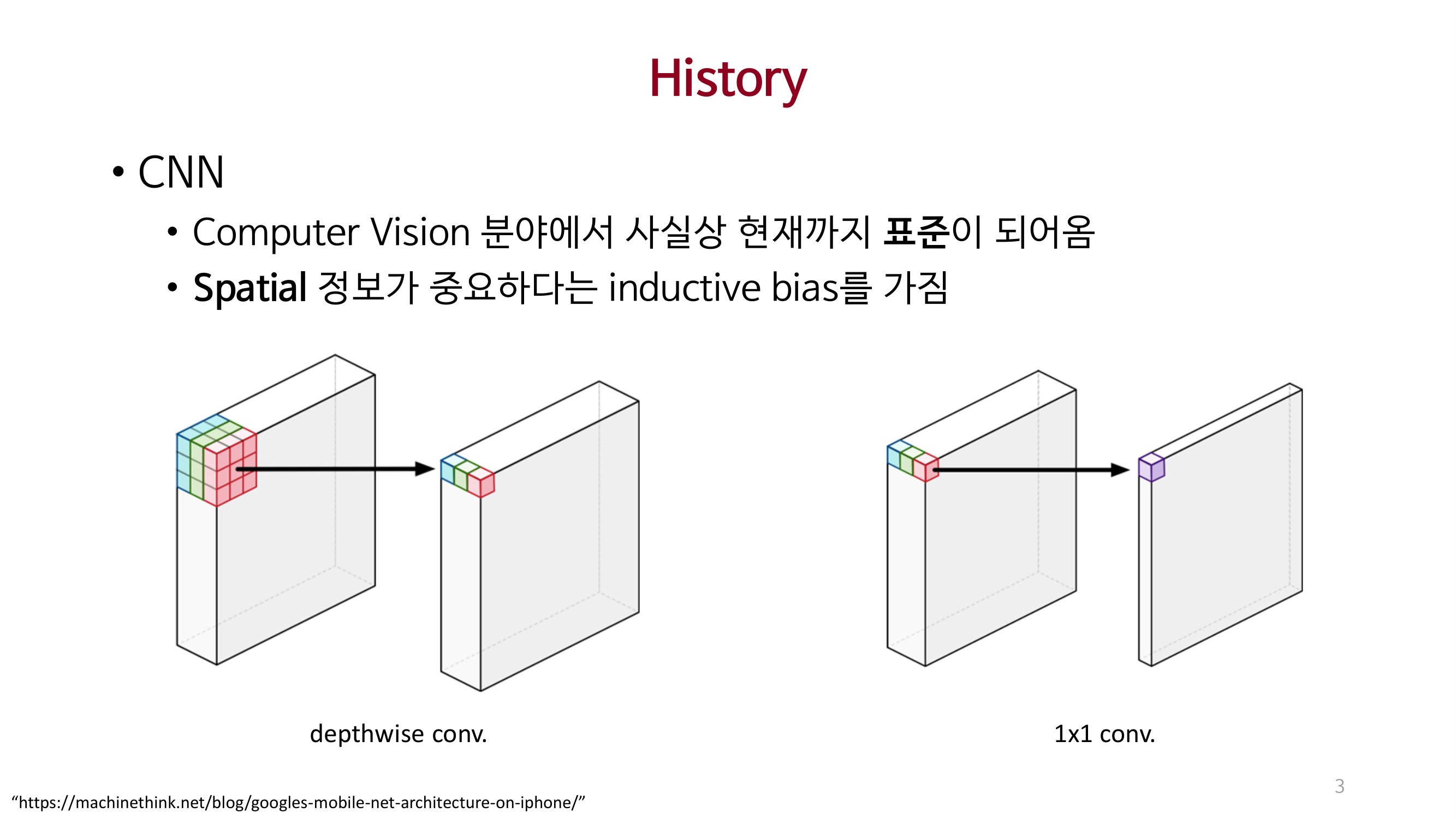
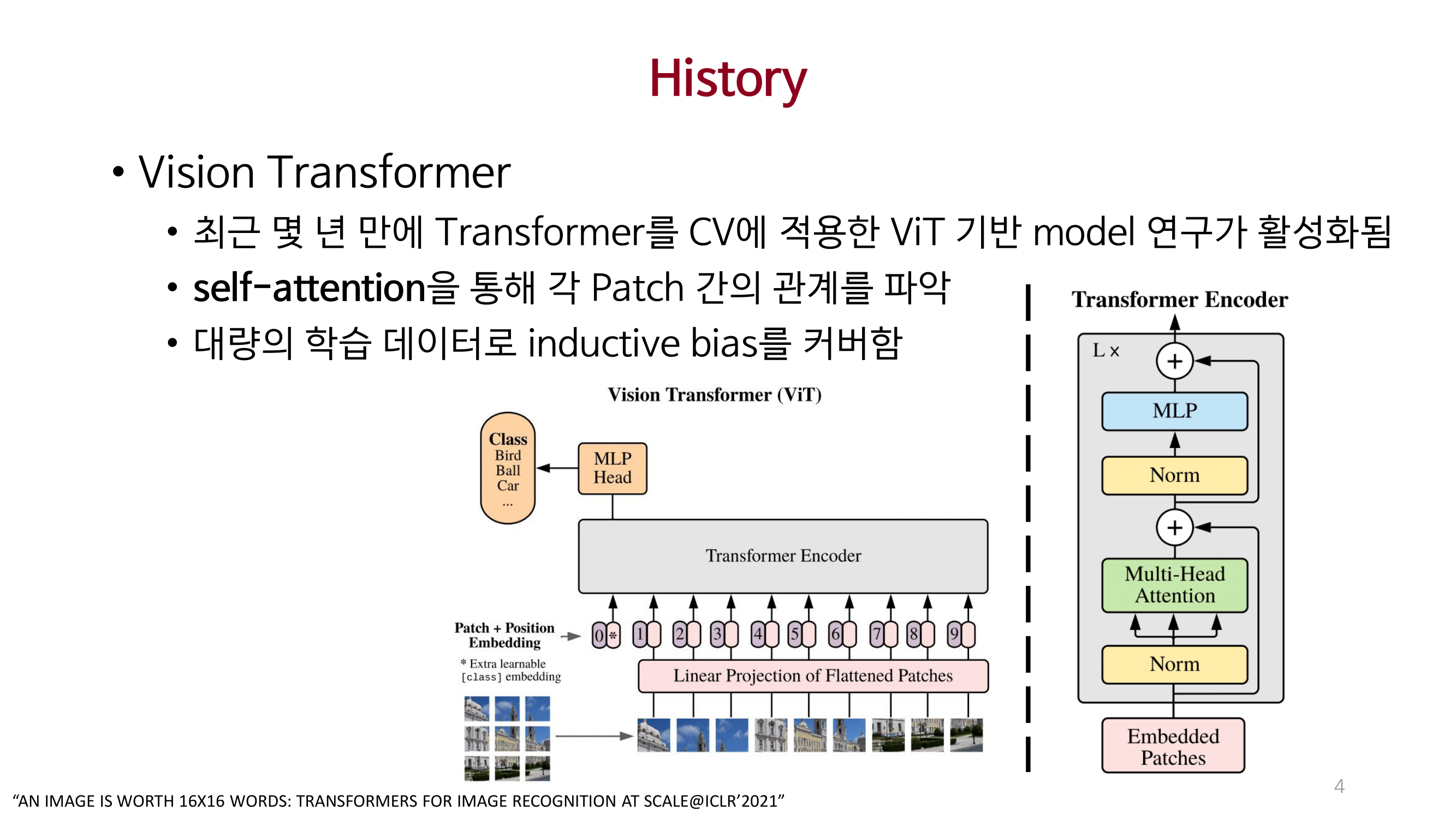



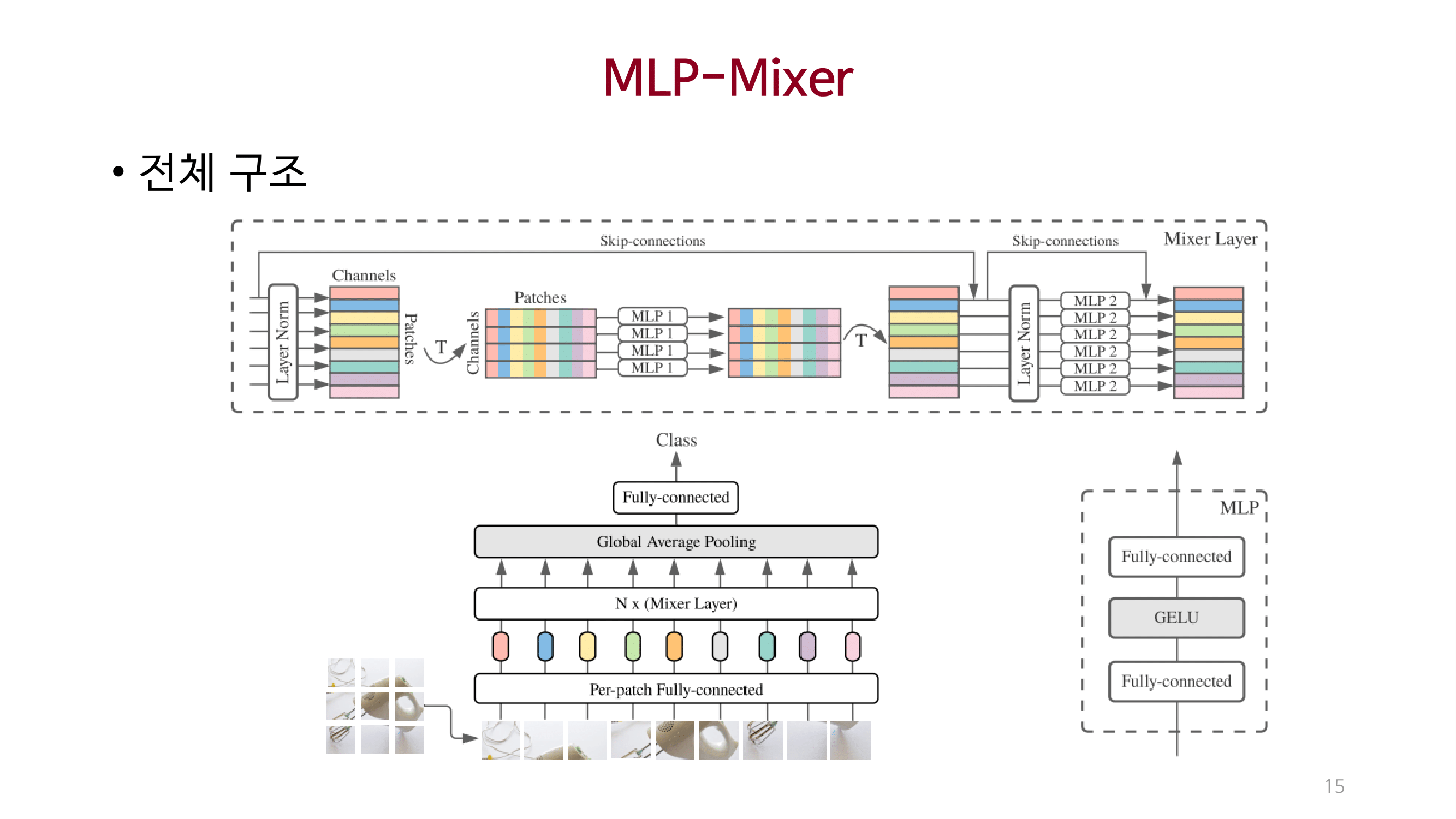
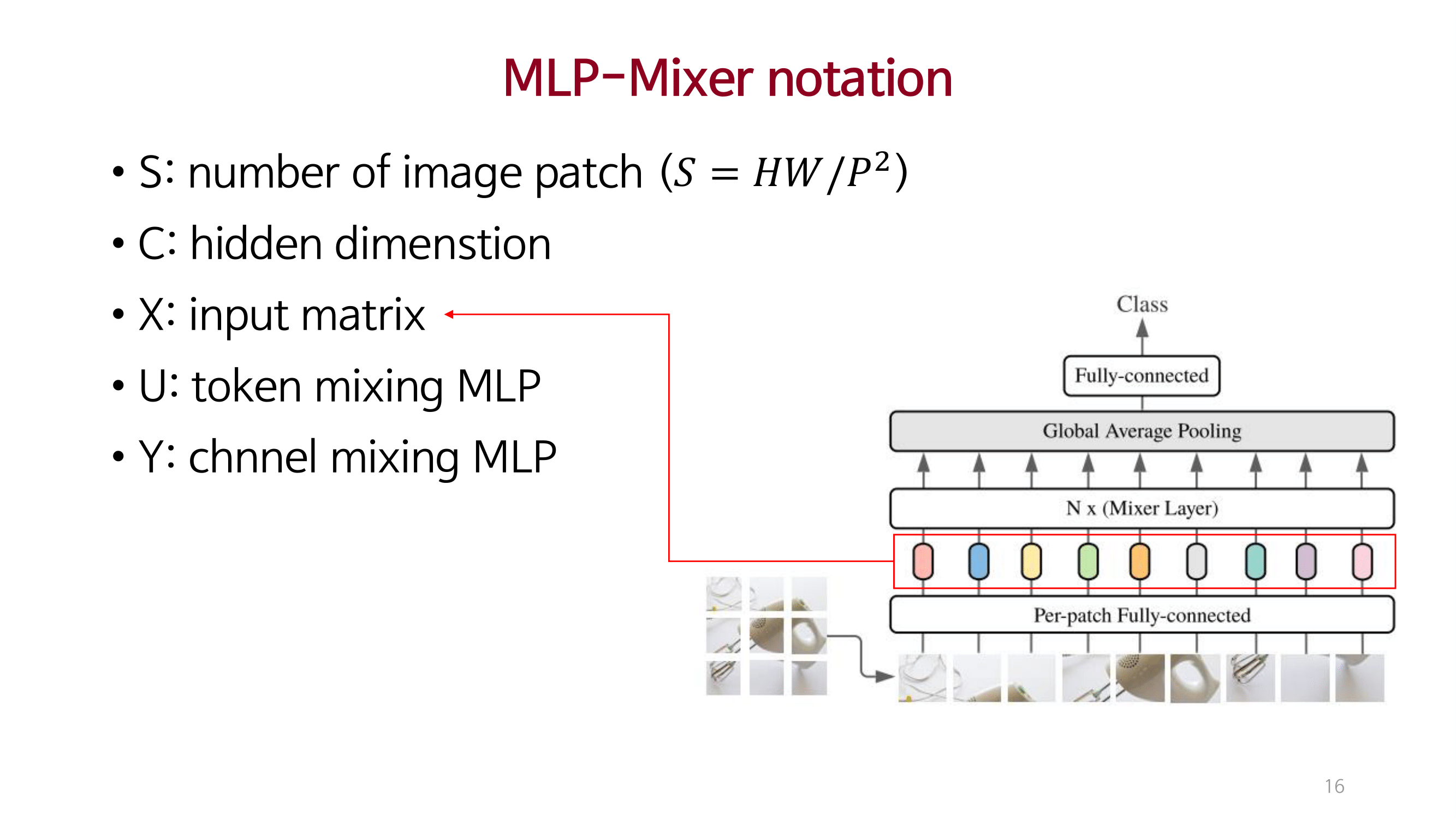
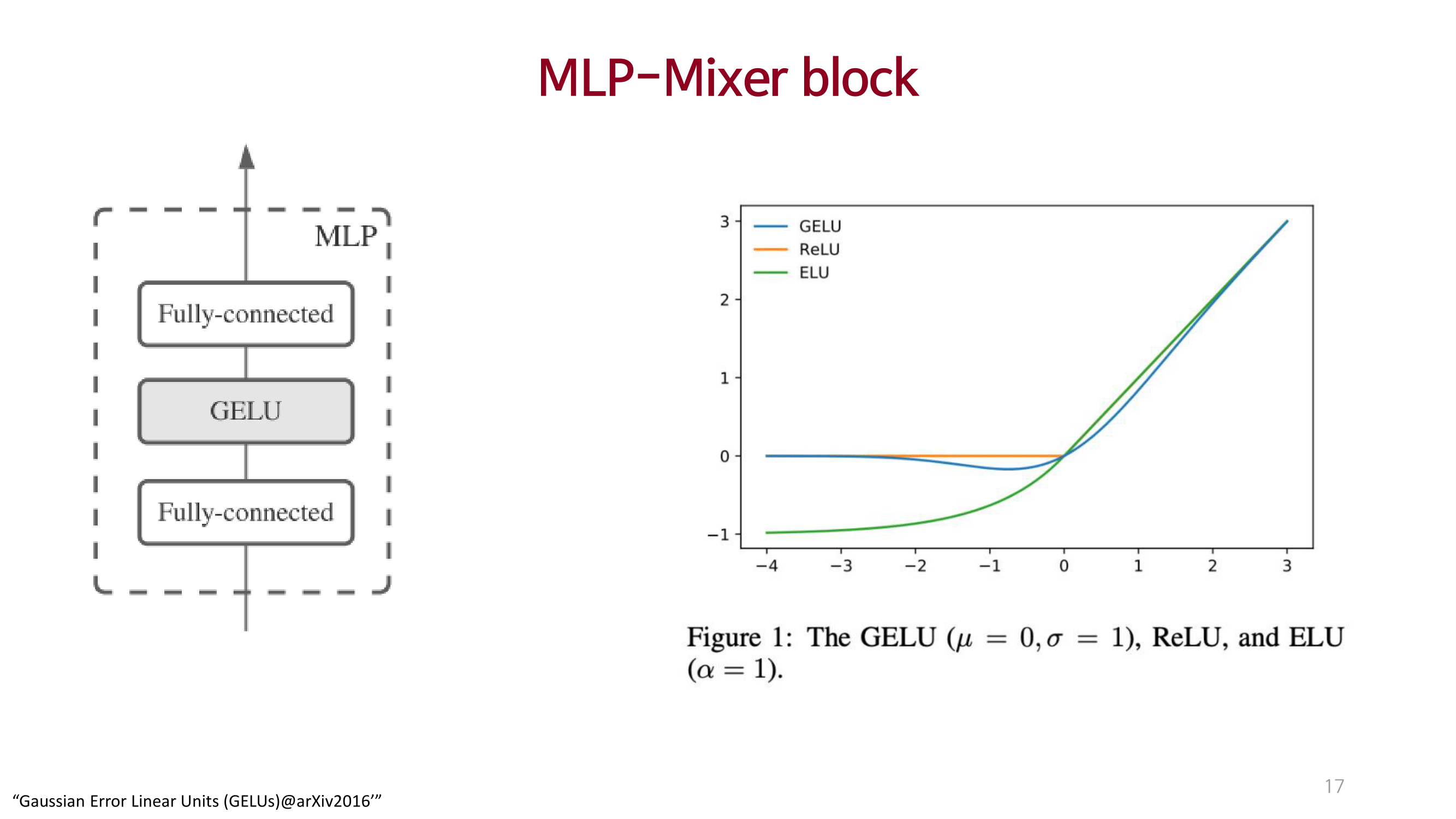
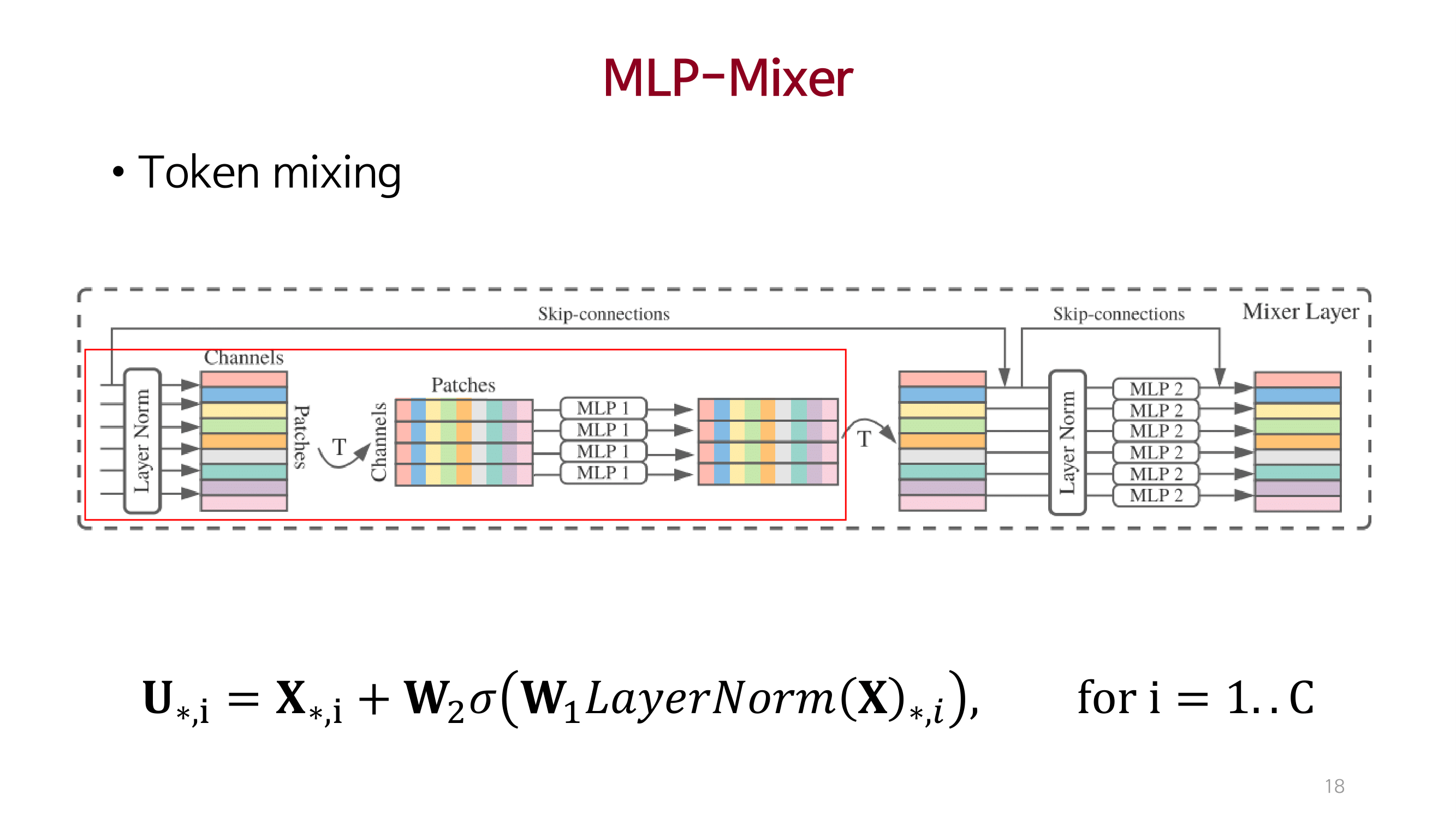
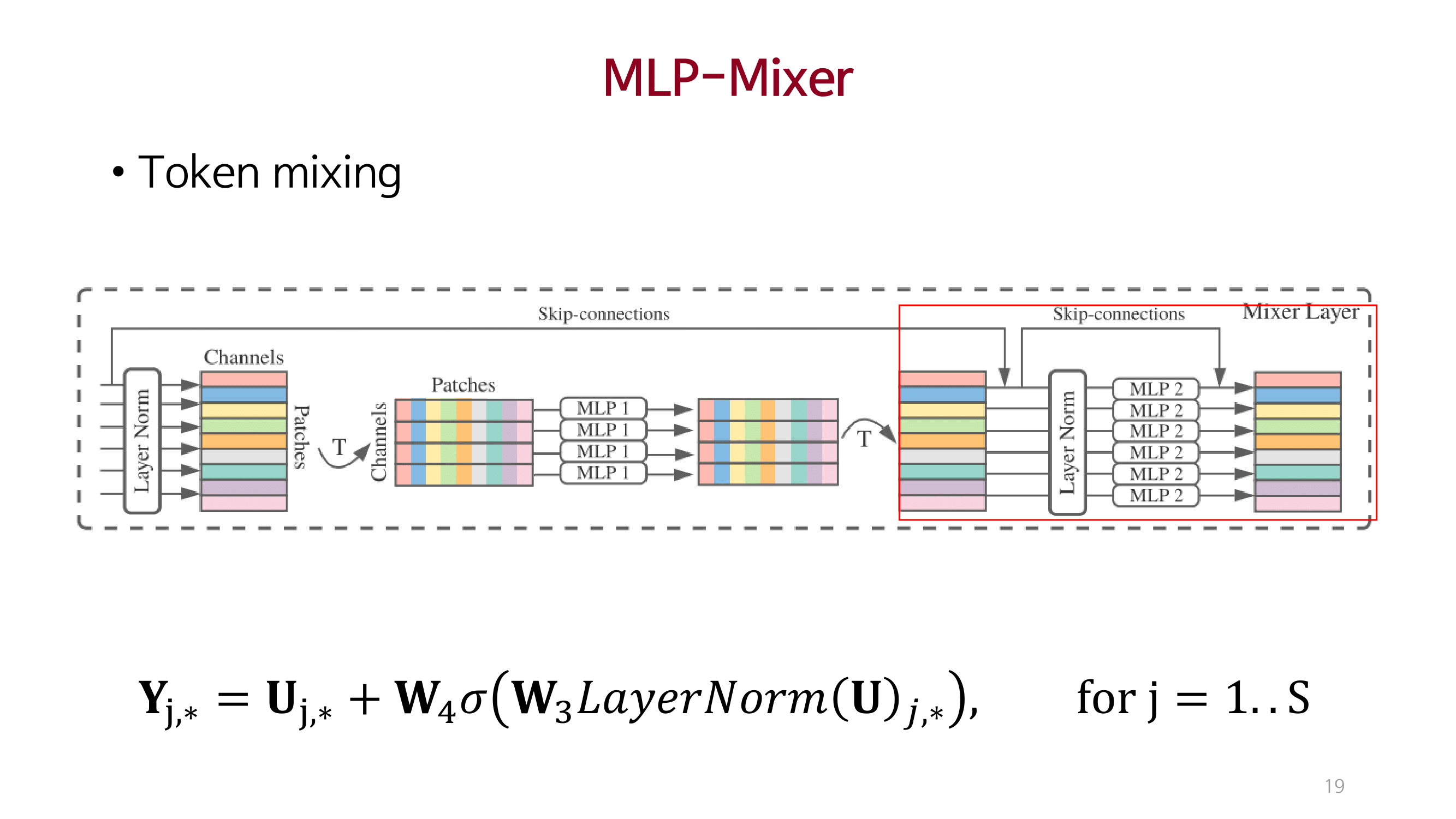
MLP_Mixer
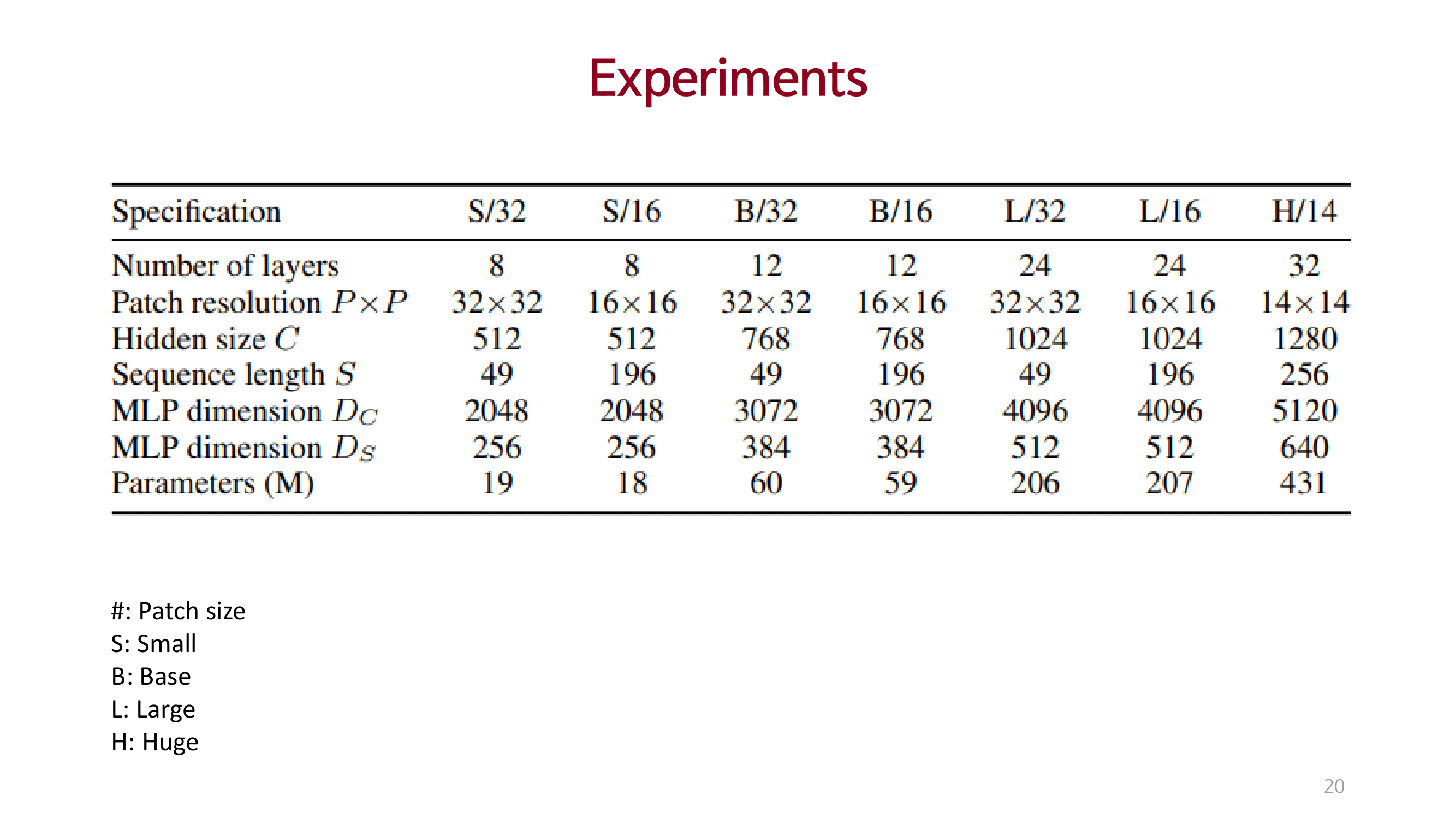
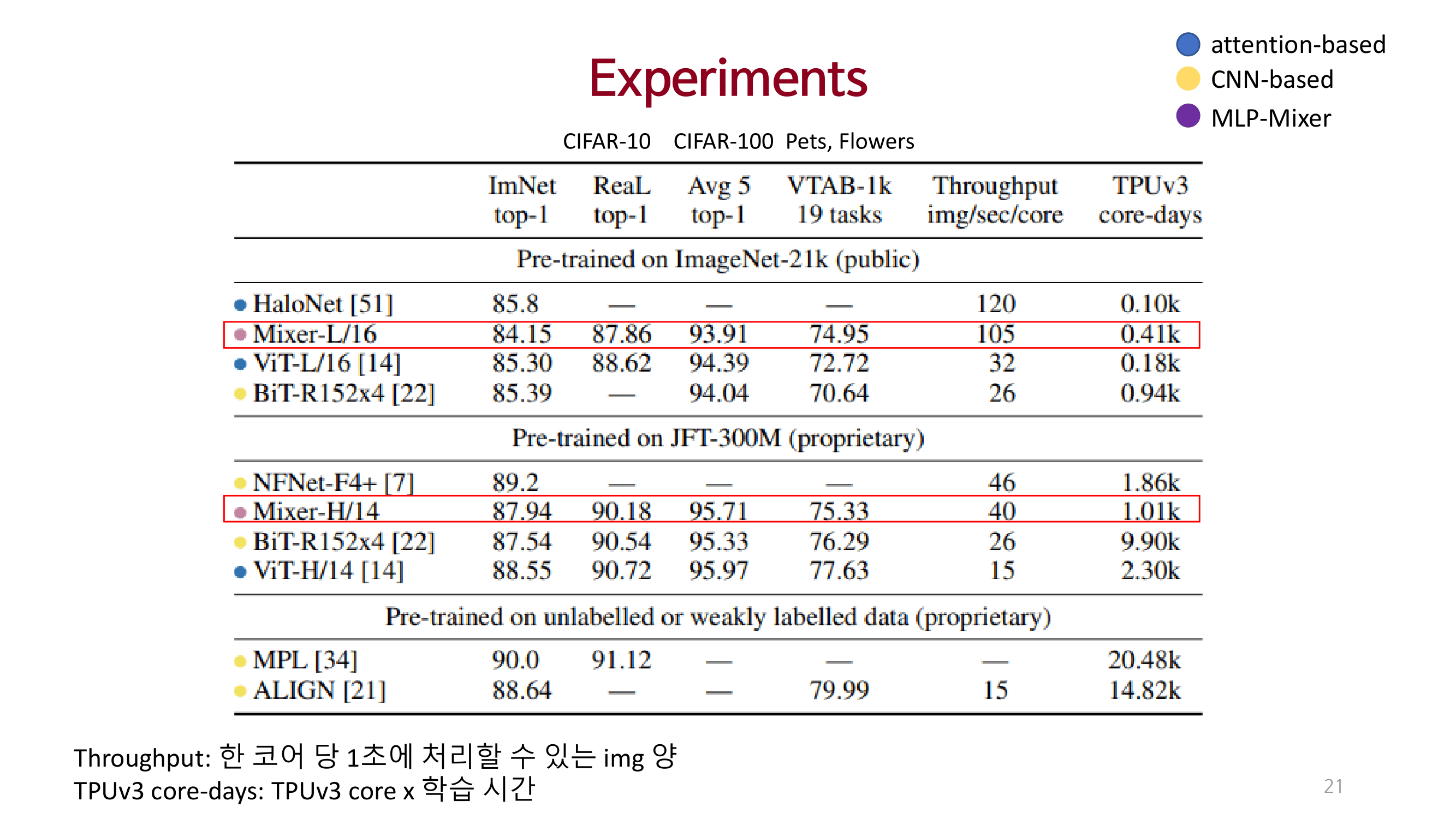
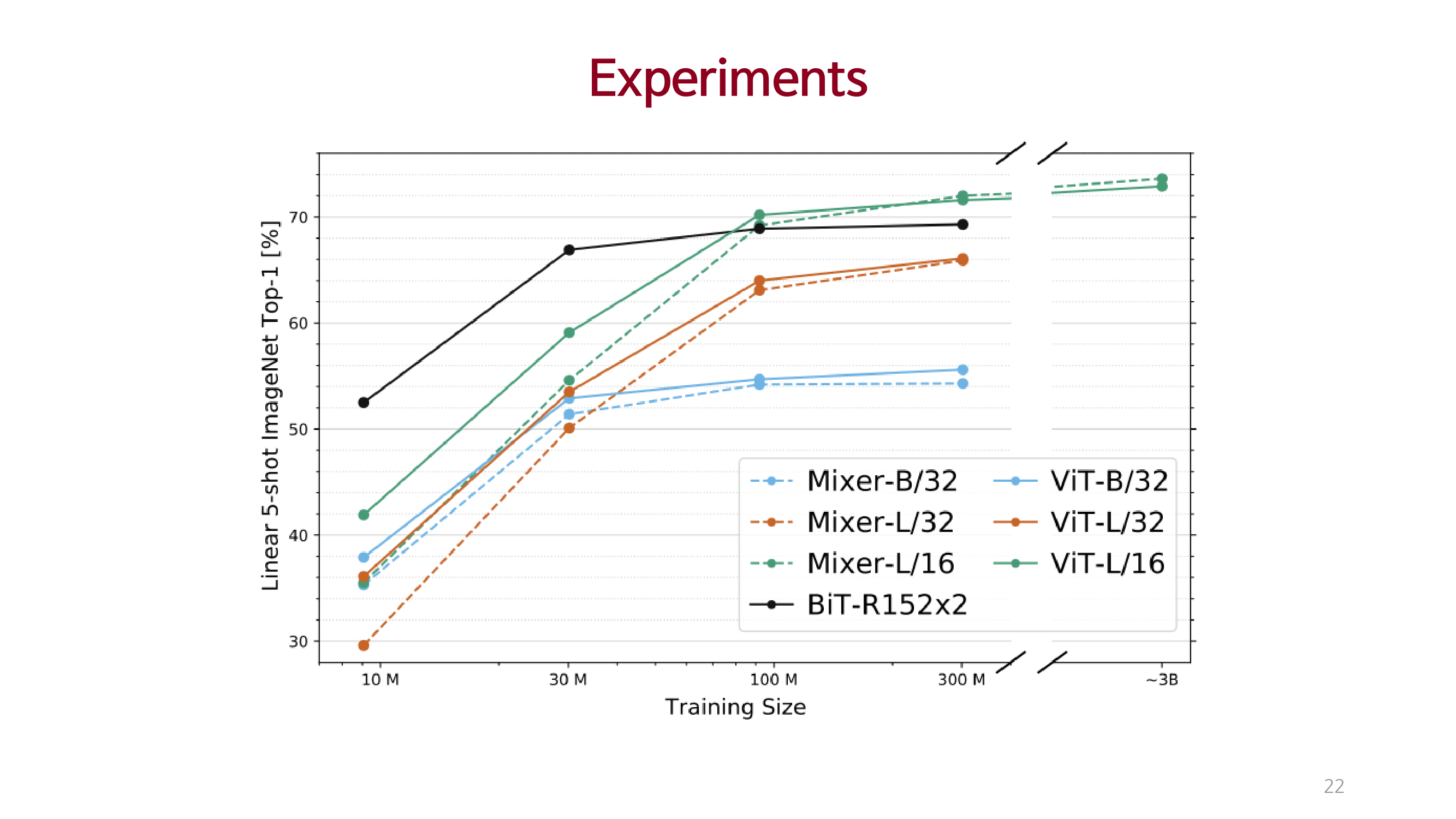
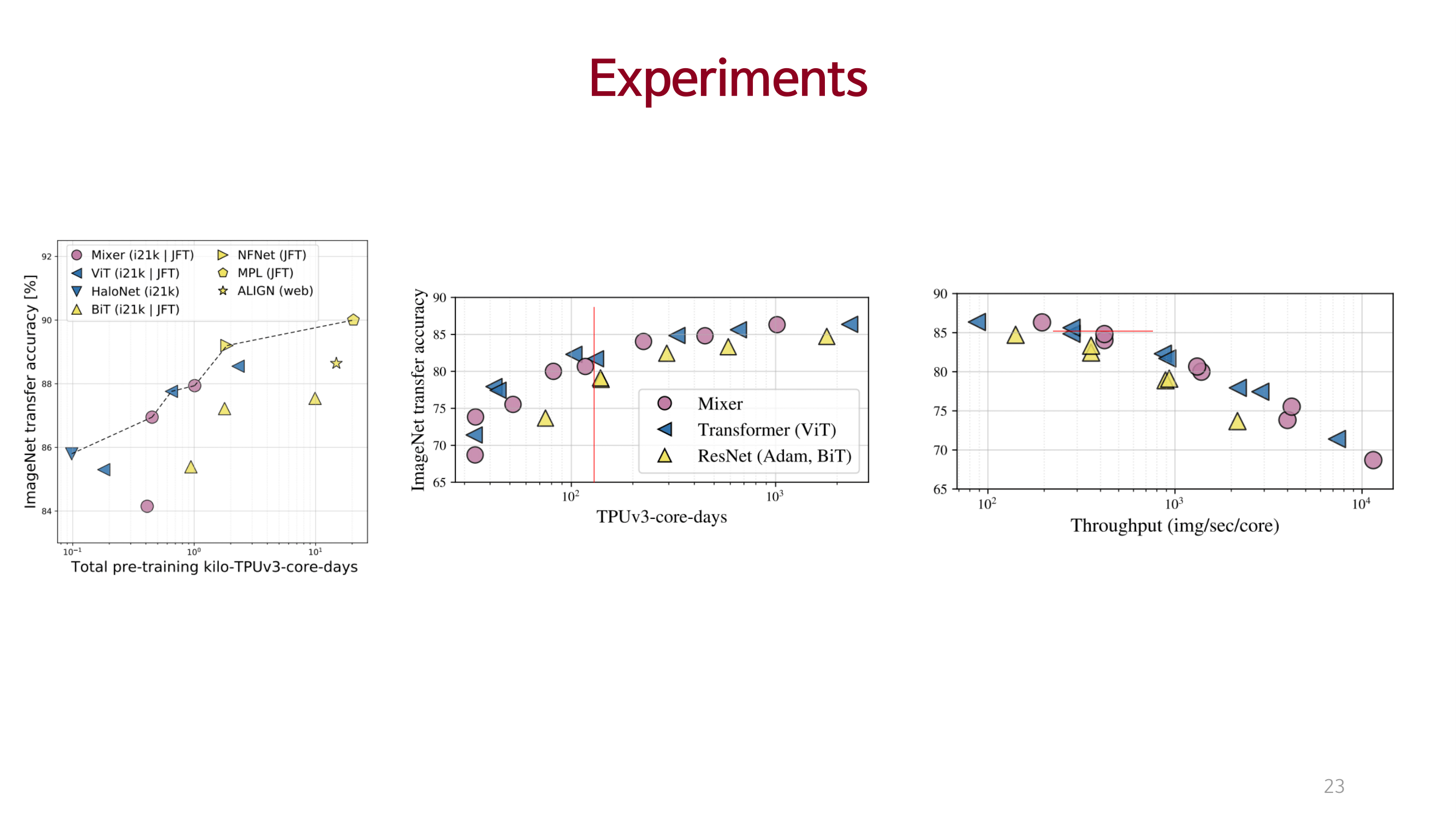
Experiments
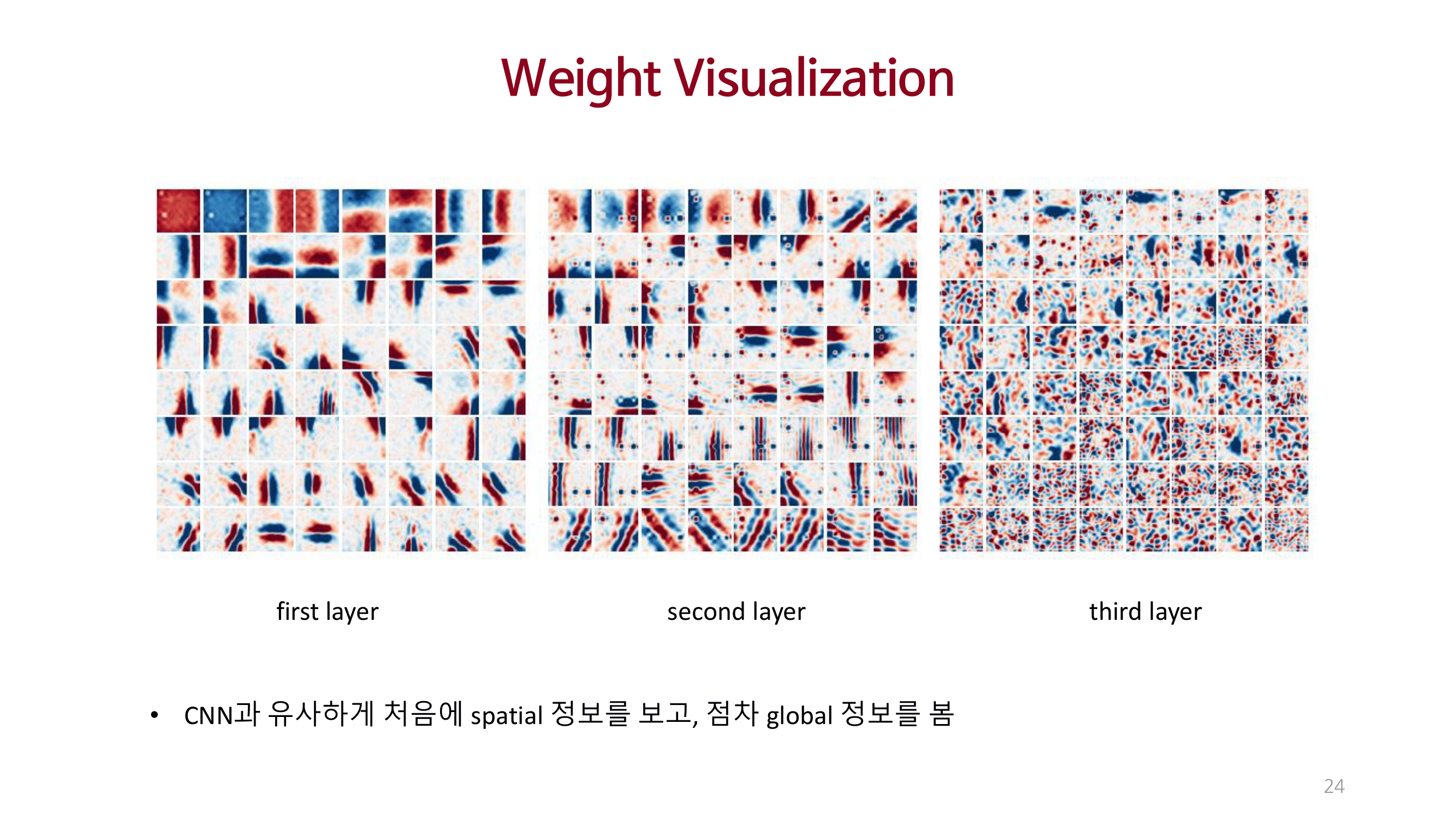
Conclusions & Reviews
CNN과 Self-attention을 사용하지 않는 MLP-Mixer를 제안함.
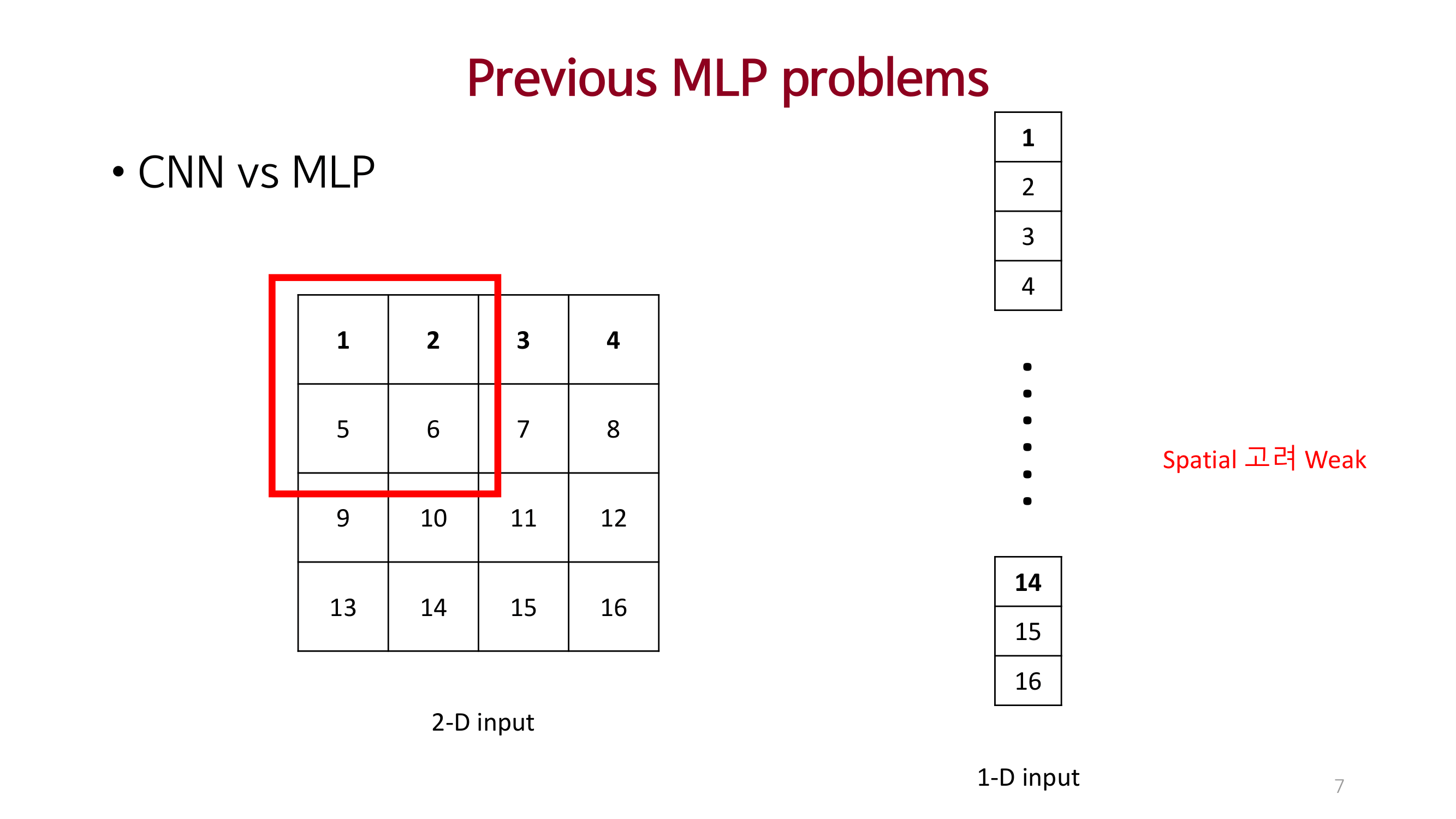
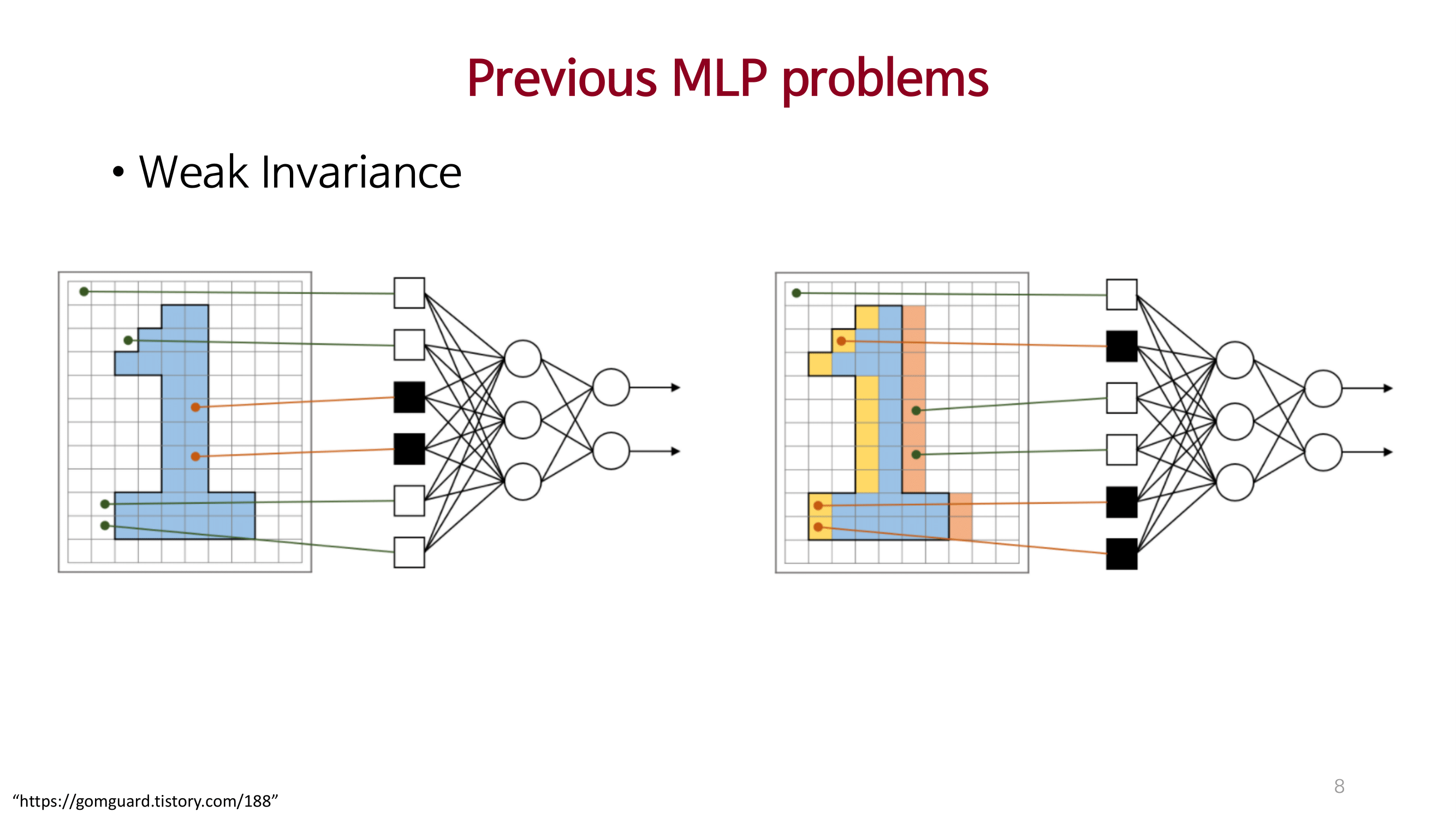
이미지 처리에 대한 2가지(Cross location, Per location) 중요점을 명시적으로 제안함.
처리량, 성능, 시간 대비 기존 SOTA 모델에 준하는 성능을 달성함.
근본적으로 돌아와서 MLP로 성능을 개선하고 처리량 등을 개선한 점이 놀라웠다.
inductive bias의 이론적 이해와 직관이 CV 연구에 어쩌면 가장 중요한 점이 아닐까라는 생각을 가졌다.
Reference
This post is licensed under CC BY 4.0 by the author.